SQL: Structured Query Language

Data & Information :
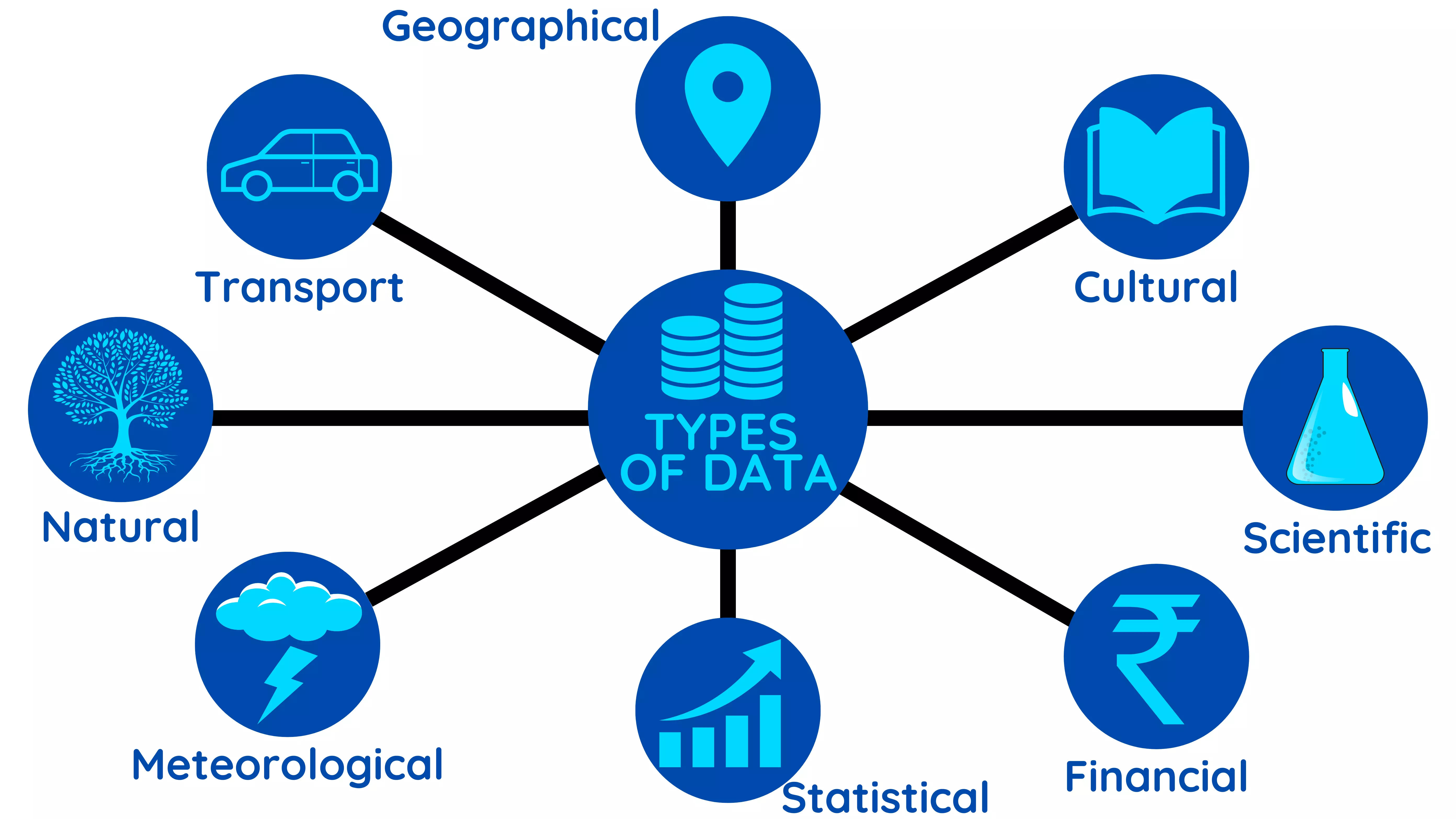
Data:
- ➤ Structured data is organized in a specific format, such as tables in a relational database, making it easy to search and analyze.
- ➤ Semi-structured data contains some structure but also includes data that doesn't conform to a specific format.
- ➤ Unstructured data, on the other hand, doesn't have any structure or format and is often difficult to search and analyze.
Information:
Convert Data to Information :
Data can be converted to information through a process of analysis and interpretation. This involves
organizing, filtering, and processing the data to extract meaningful insights and patterns that can be used to
make informed decisions.
Here are some steps involved in converting data to information:
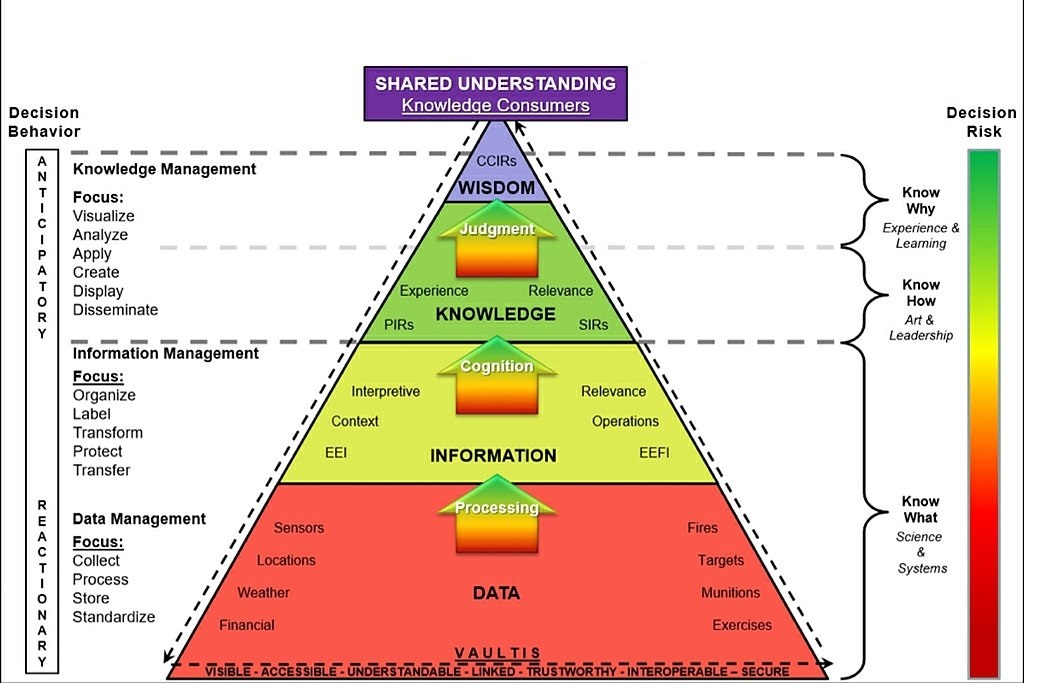
DIKW Pyramid :
KM Cognitive Pyramid
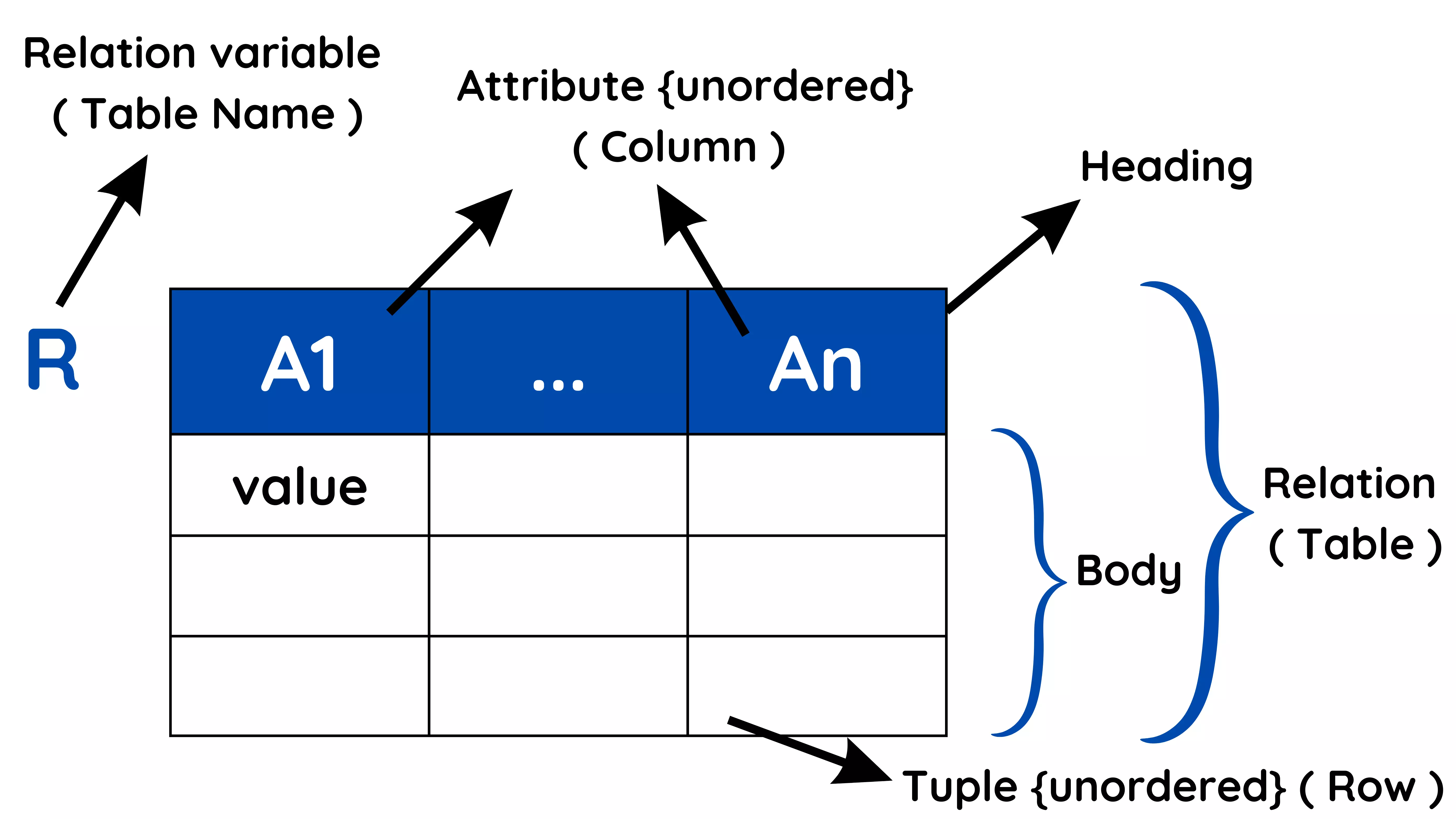
Database
Example:
Students Database organizes the data about the students, Courses, etc.
Employee Database organizes the data about the employees, salary, department etc.
DBMS - DataBase Management System
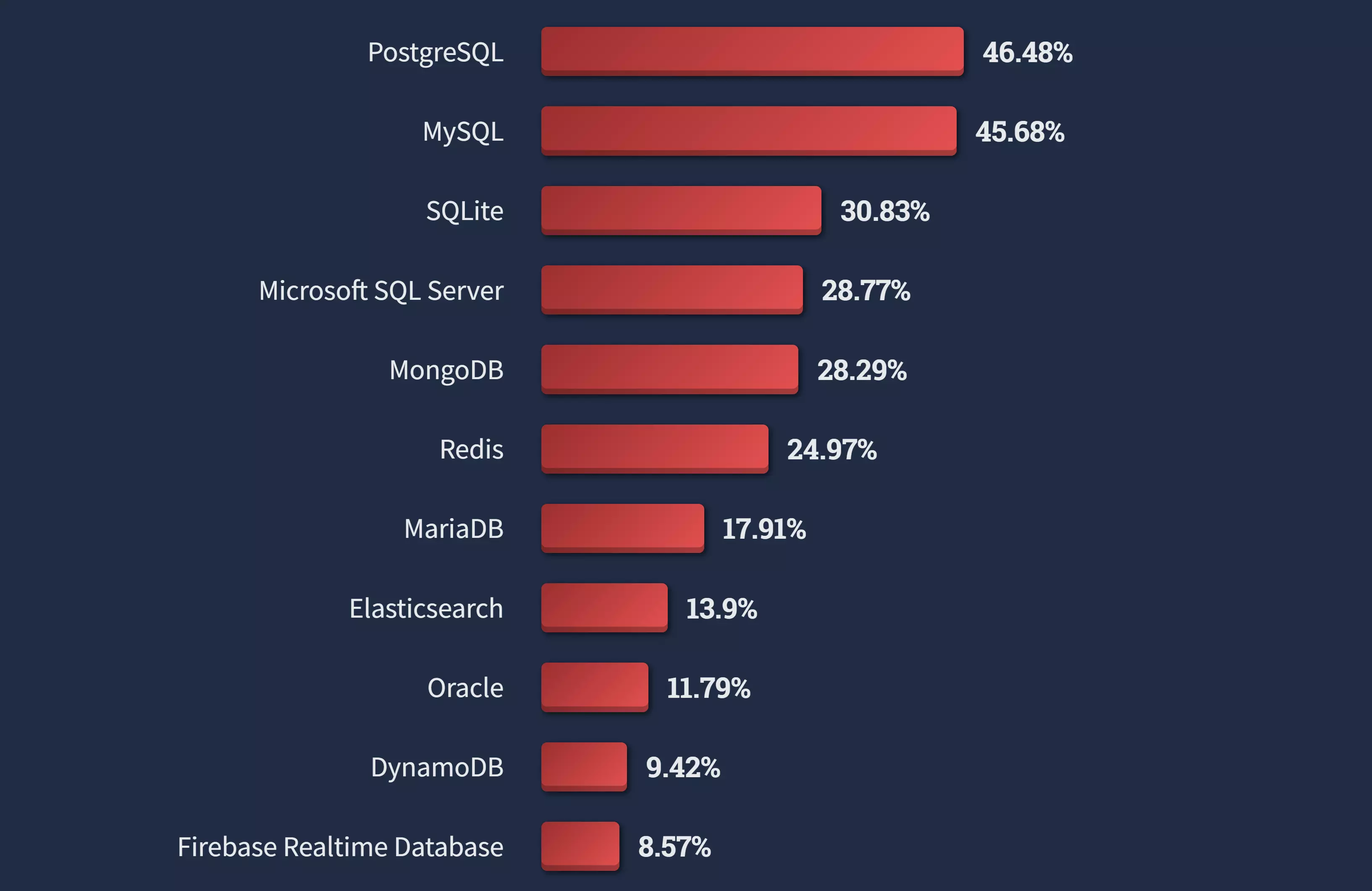
Examples of DBMS:

Stack Overflow Survey 2022: Database environments that professional developers have done extensive development work in over the past year, and they want to work in over the next year.
History of DBMS
Applications of DBMS
DBMSs are used to store, manage, and retrieve data, and to provide quick and easy access to data for
decision-making, analysis, and reporting purposes.
Characteristics of DBMS
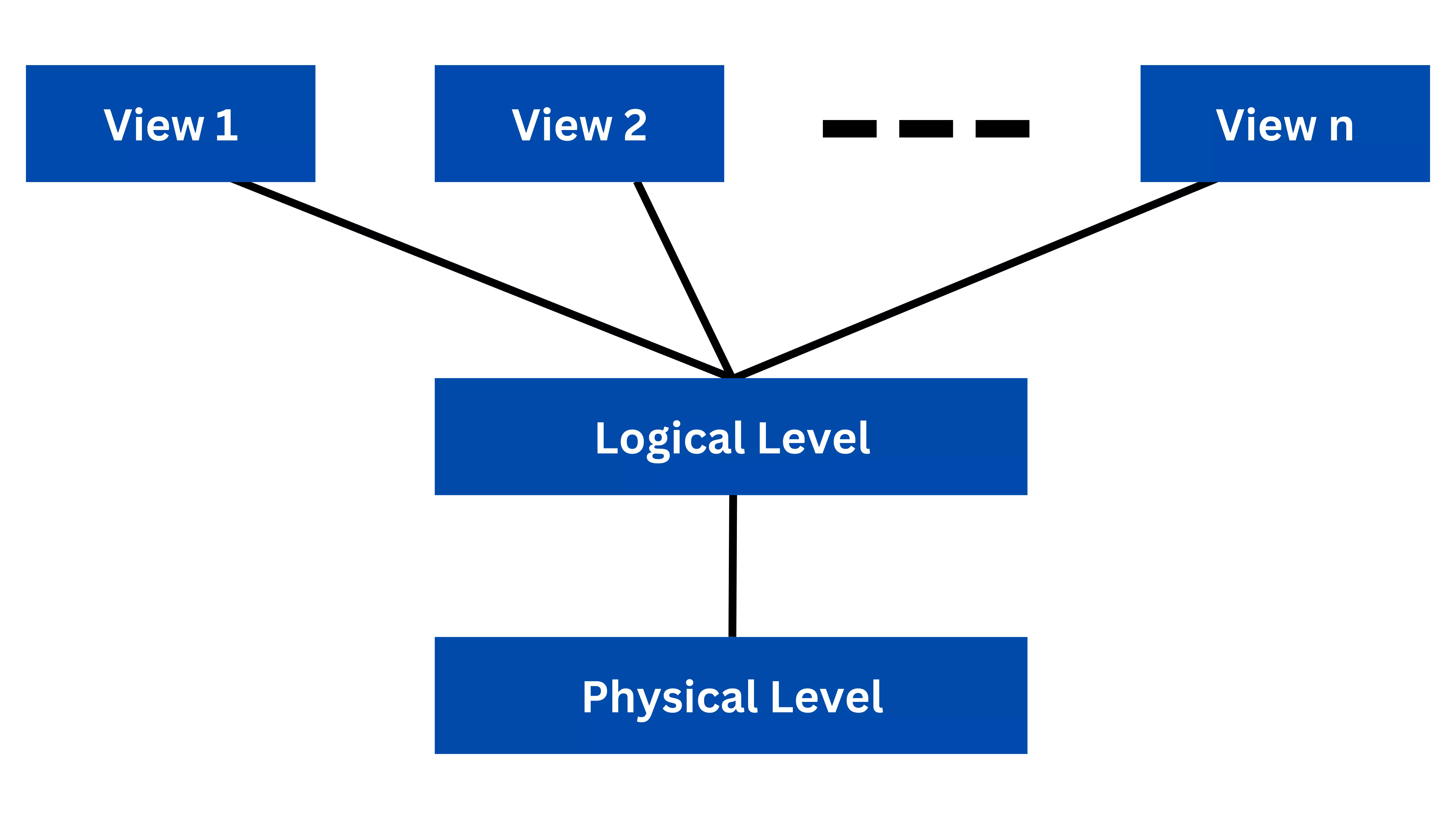
Data Abstraction in DBMS
Data abstraction is a fundamental concept in DBMS (Database Management System) that refers to the process of hiding the complexity of the data stored in a database from the end-user. It provides a level of abstraction that allows users to interact with the data without having to understand its underlying complexity.
There are three levels of data abstraction in DBMS:
Data Modelling
Define Data Modeling
Types of data models
Like any design process, database and information system design begins at a high level of abstraction and becomes increasingly more concrete and specific. Data models can generally be divided into three categories, which vary according to their degree of abstraction. The process will start with a conceptual model, progress to a logical model and conclude with a physical model. Each type of data model is discussed in more detail below:
Data modeling process
As a discipline, data modeling invites stakeholders to evaluate data processing and storage in painstaking detail. Data modeling techniques have different conventions that dictate which symbols are used to represent the data, how models are laid out, and how business requirements are conveyed. All approaches provide formalized workflows that include a sequence of tasks to be performed in an iterative manner. Those workflows generally look like this:
- 1. Identify the entities: The process of data modeling begins with the identification of the things, events or concepts that are represented in the data set that is to be modeled. Each entity should be cohesive and logically discrete from all others.
- 2. Identify key properties of each entity: Each entity type can be differentiated from all others because it has one or more unique properties, called attributes. For instance, an entity called “customer” might possess such attributes as a first name, last name, telephone number and salutation, while an entity called “address” might include a street name and number, a city, state, country and zip code.
- 3. Identify relationships among entities: The earliest draft of a data model will specify the nature of the relationships each entity has with the others. In the above example, each customer “lives at” an address. If that model were expanded to include an entity called “orders,” each order would be shipped to and billed to an address as well. These relationships are usually documented via unified modeling language (UML).
- 4. Map attributes to entities completely: This will ensure the model reflects how the business will use the data. Several formal data modeling patterns are in widespread use. Object-oriented developers often apply analysis patterns or design patterns, while stakeholders from other business domains may turn to other patterns.
- 5. Assign keys as needed, and decide on a degree of normalization that balances the need to reduce redundancy with performance requirements: Normalization is a technique for organizing data models (and the databases they represent) in which numerical identifiers, called keys, are assigned to groups of data to represent relationships between them without repeating the data. For instance, if customers are each assigned a key, that key can be linked to both their address and their order history without having to repeat this information in the table of customer names. Normalization tends to reduce the amount of storage space a database will require, but it can at cost to query performance.
- 6. Finalize and validate the data model: Data modeling is an iterative process that should be repeated and refined as business needs change.
Types of data modeling
Data modeling has evolved alongside database management systems, with model types increasing in complexity as businesses' data storage needs have grown. Here are several model types:
Two popular dimensional data models are the star schema, in which data is organized into facts (measurable items) and dimensions (reference information), where each fact is surrounded by its associated dimensions in a star-like pattern. The other is the snowflake schema, which resembles the star schema but includes additional layers of associated dimensions, making the branching pattern more complex.
Benefits of data modeling
Data modeling makes it easier for developers, data architects, business analysts, and other stakeholders to view and understand relationships among the data in a database or data warehouse. In addition, it can:
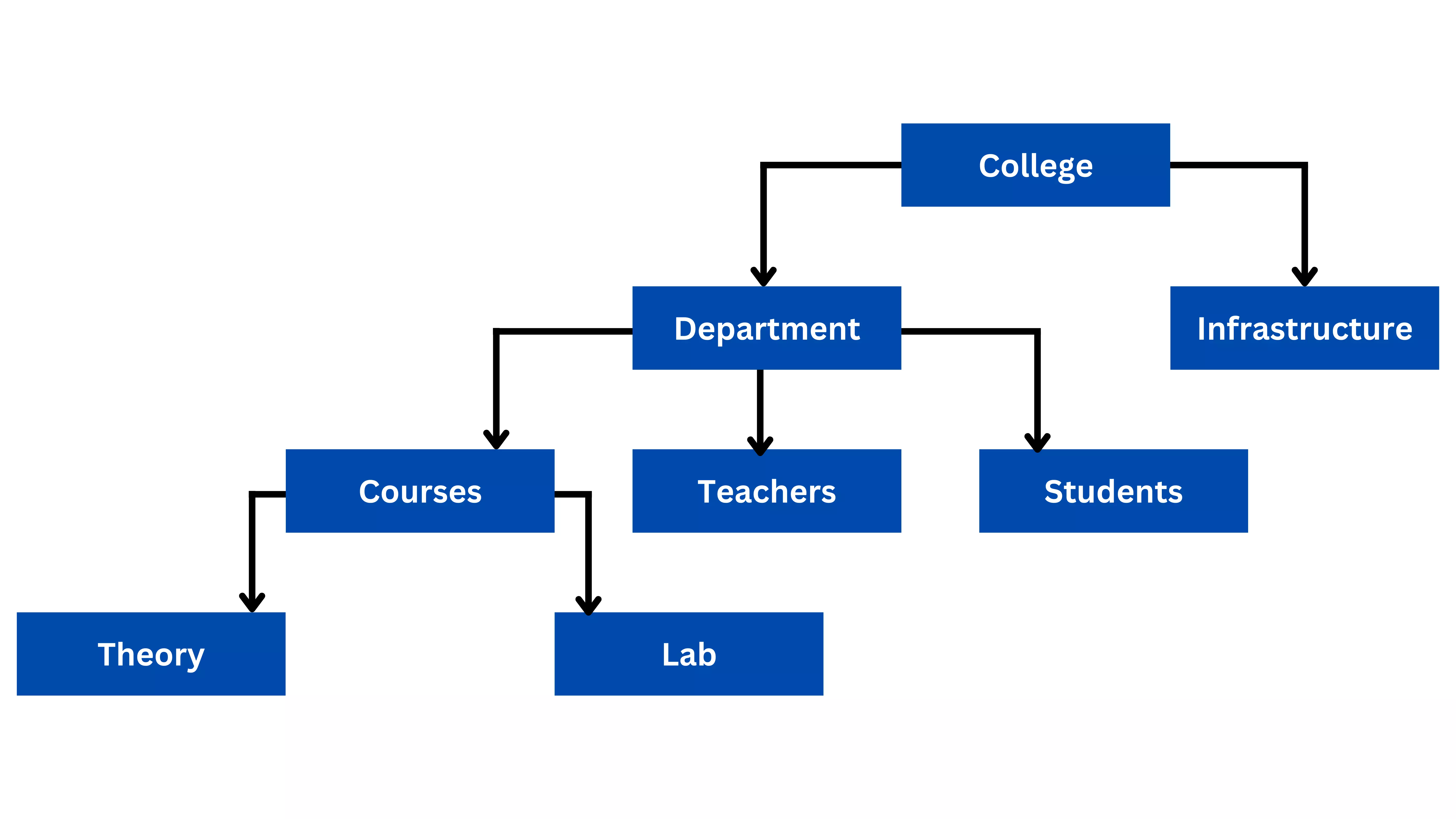
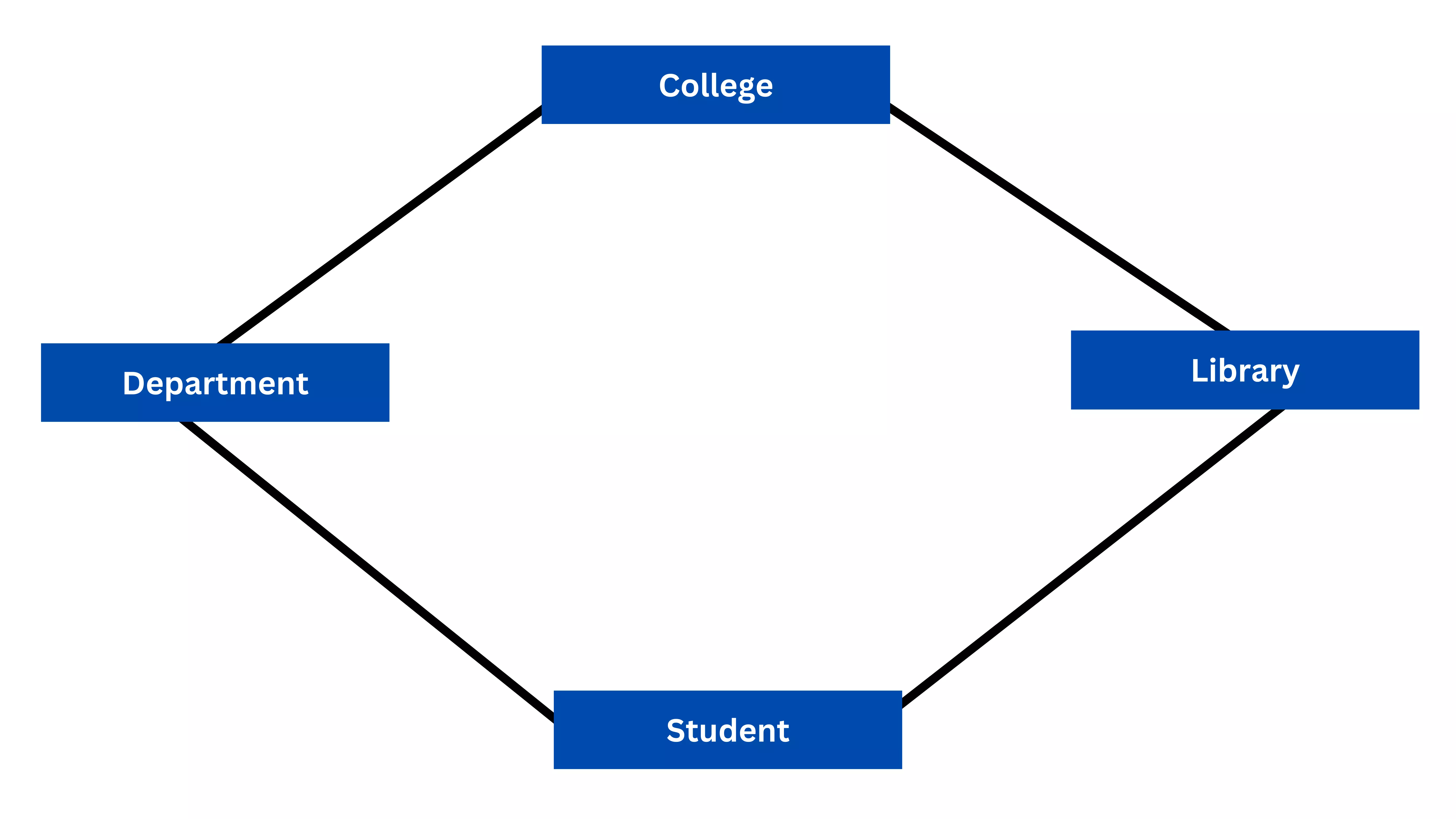
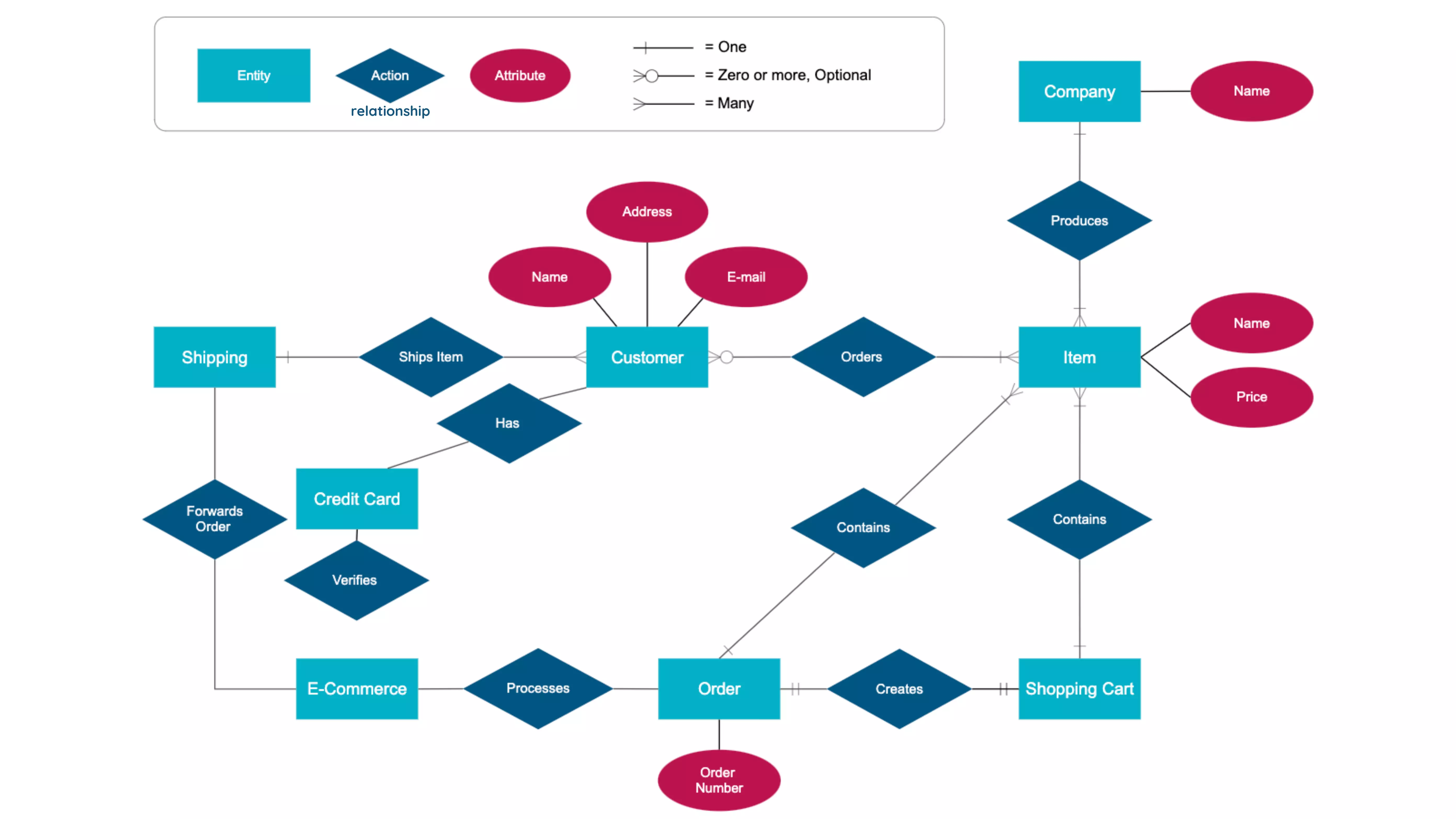
ER Diagram
What is an ER diagram?
Uses of ER Diagrams
Components and features of ERD
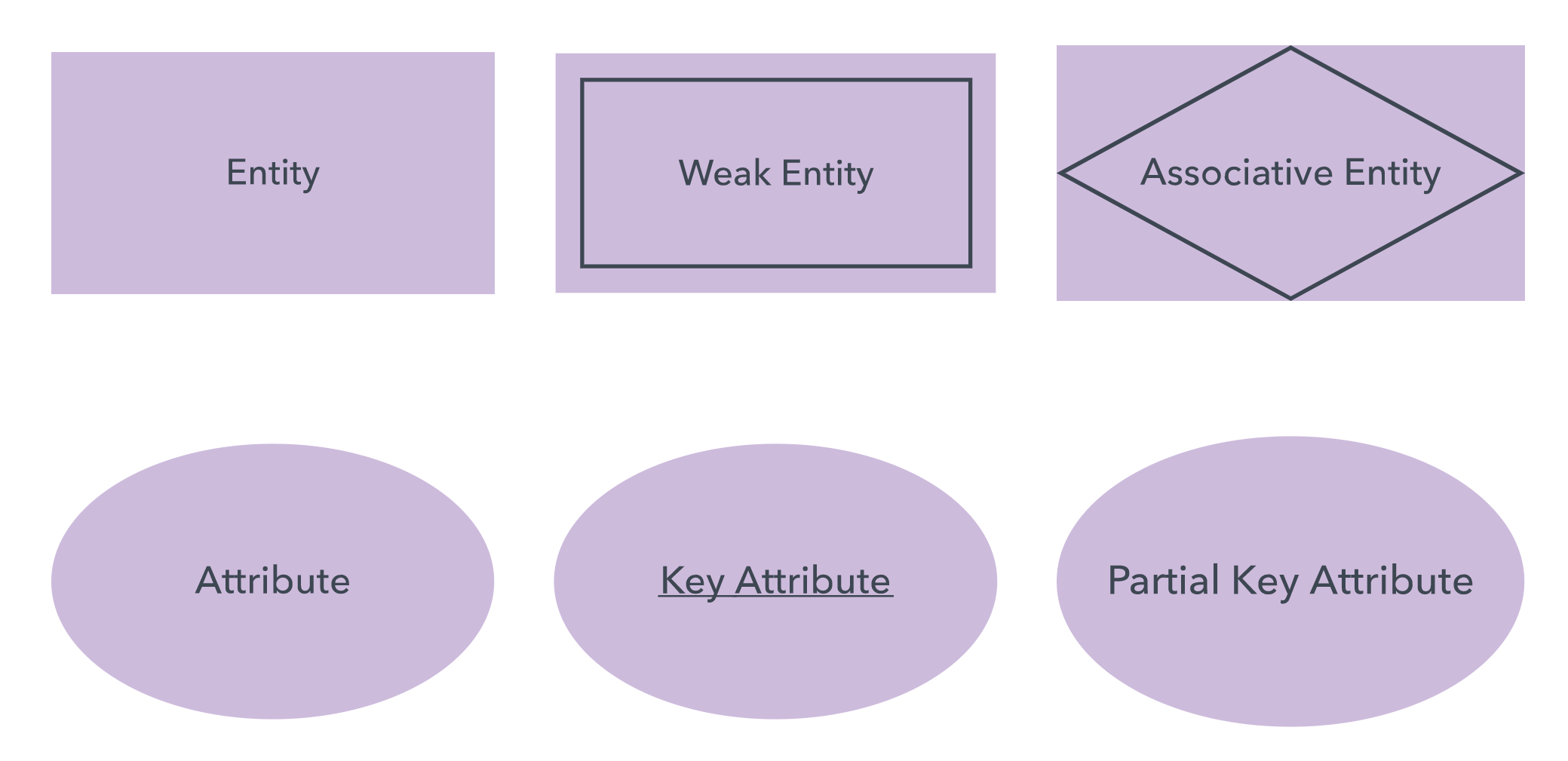
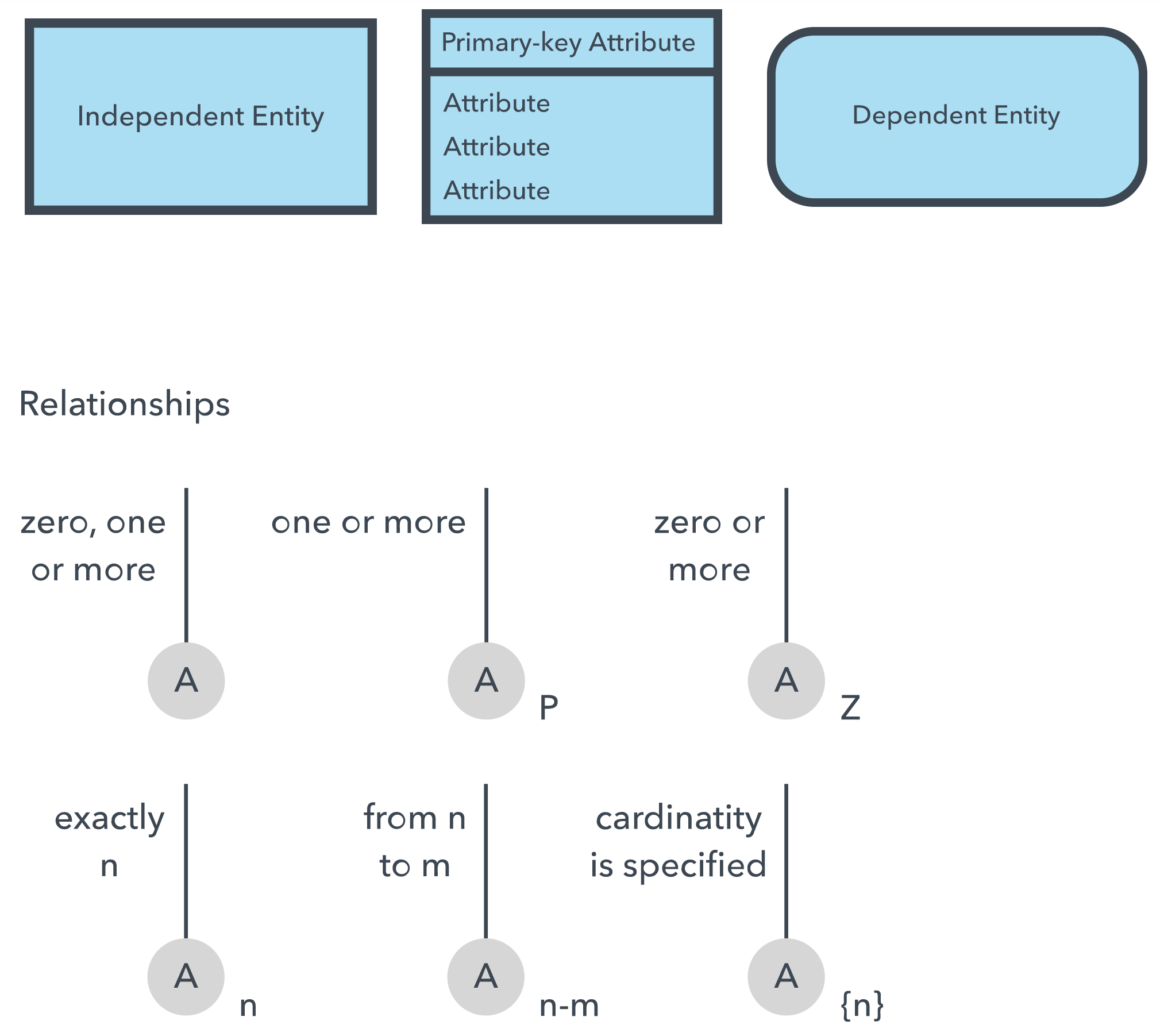
Entity:
definable thing—such as a person, object, concept or event—that can have
data stored about it. Think of entities as nouns. Examples: a customer, student, car or product. Typically
shown as a rectangle.
Relationship:
Attribute:
A property or characteristic of an entity. Often shown as an oval or
circle.
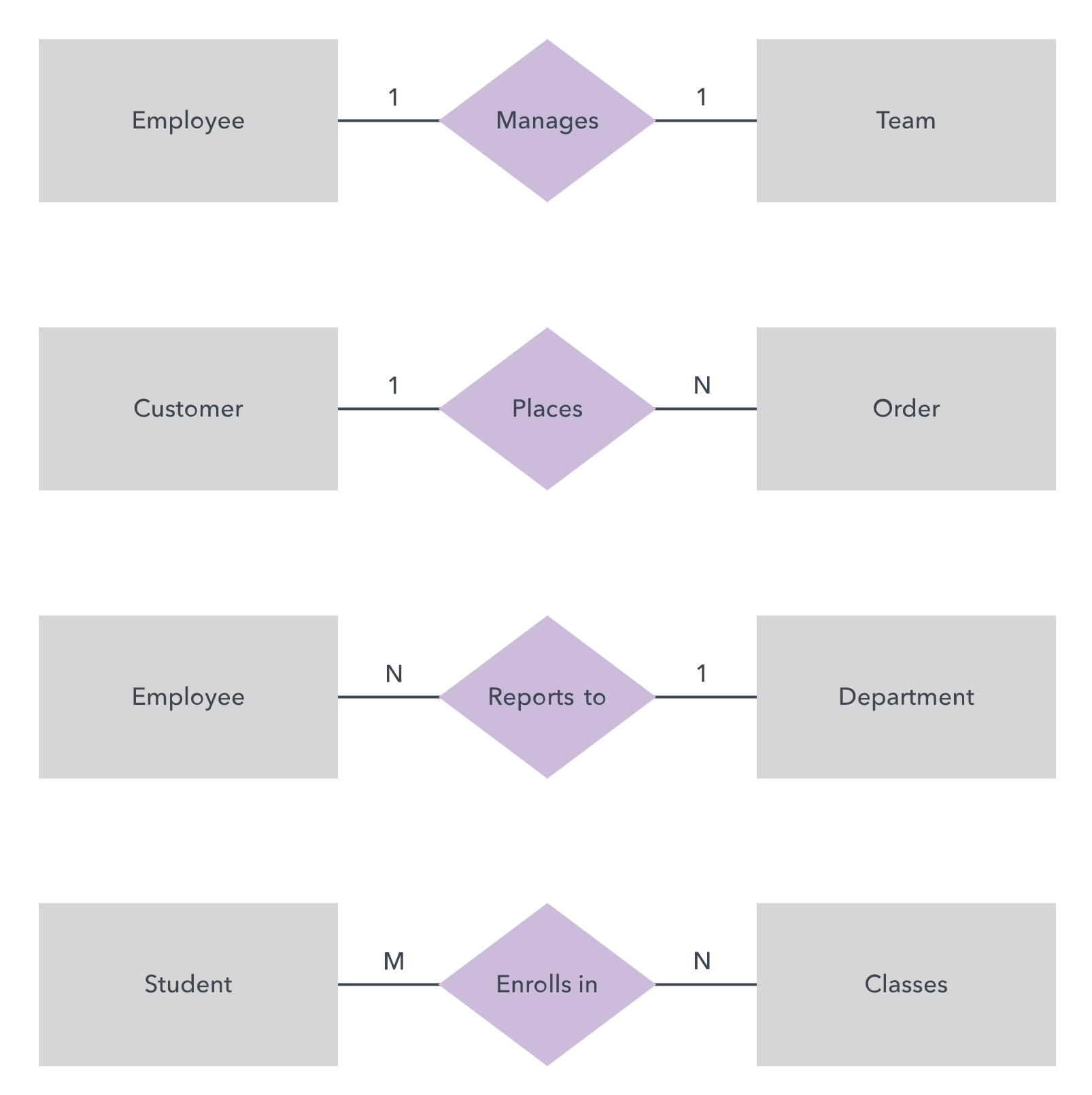
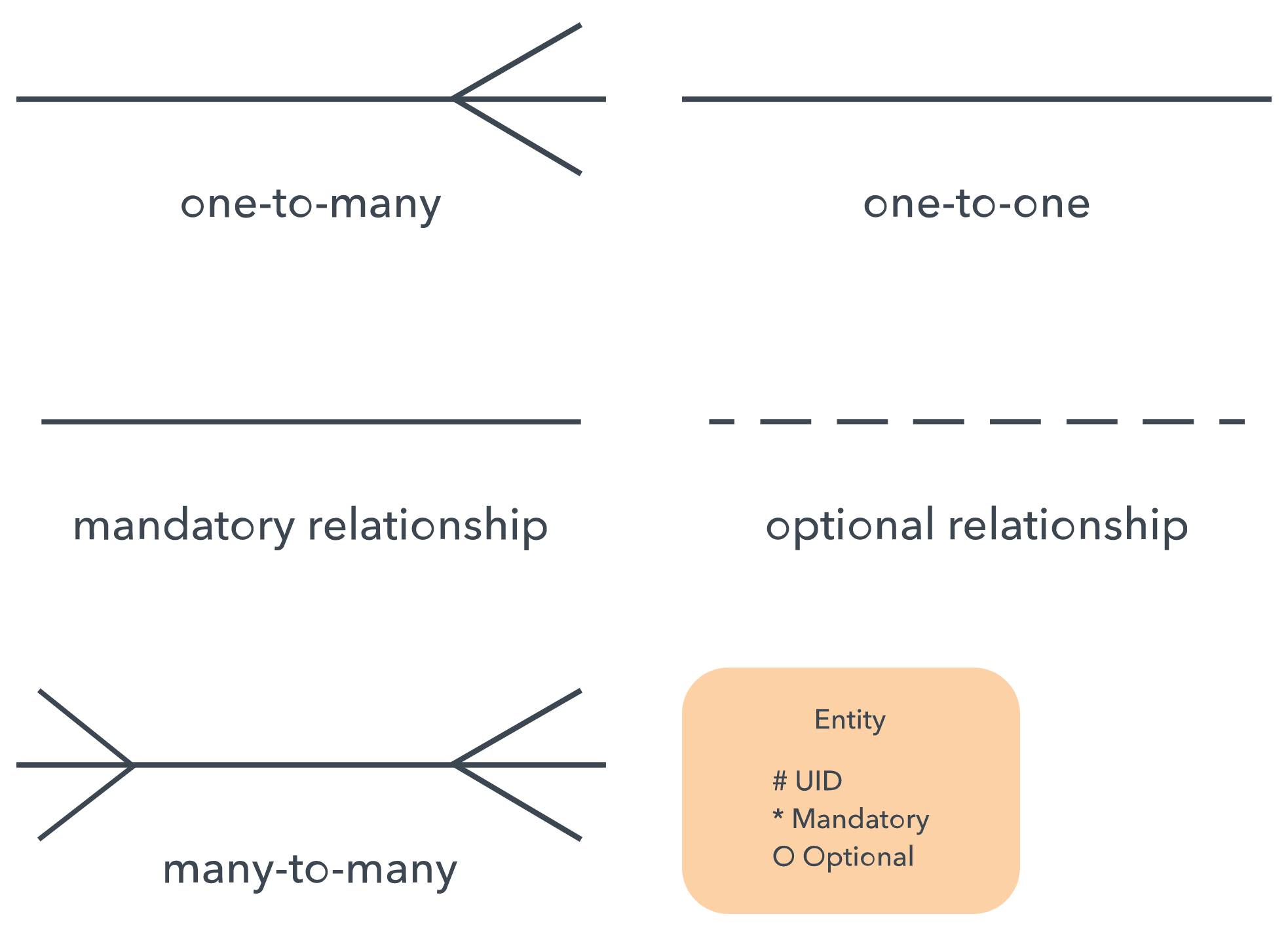
Cardinality:
- A one-to-one example would be one student associated with one mailing address.
- A one-to-many example (or many-to-one, depending on the relationship direction): One student registers for multiple courses, but all those courses have a single line back to that one student.
- Many-to-many example: Students as a group are associated with multiple faculty members, and faculty members in turn are associated with multiple students.
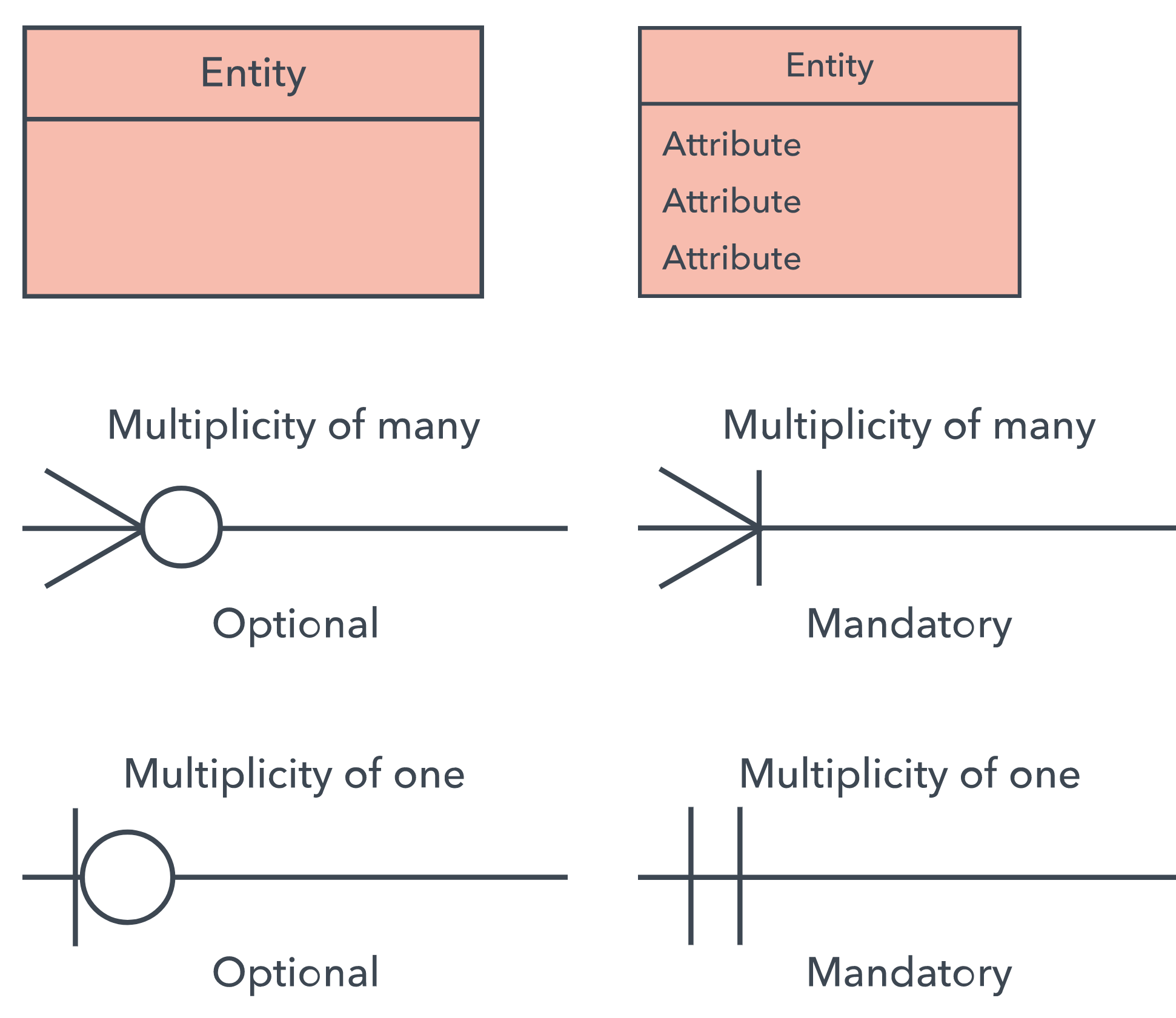
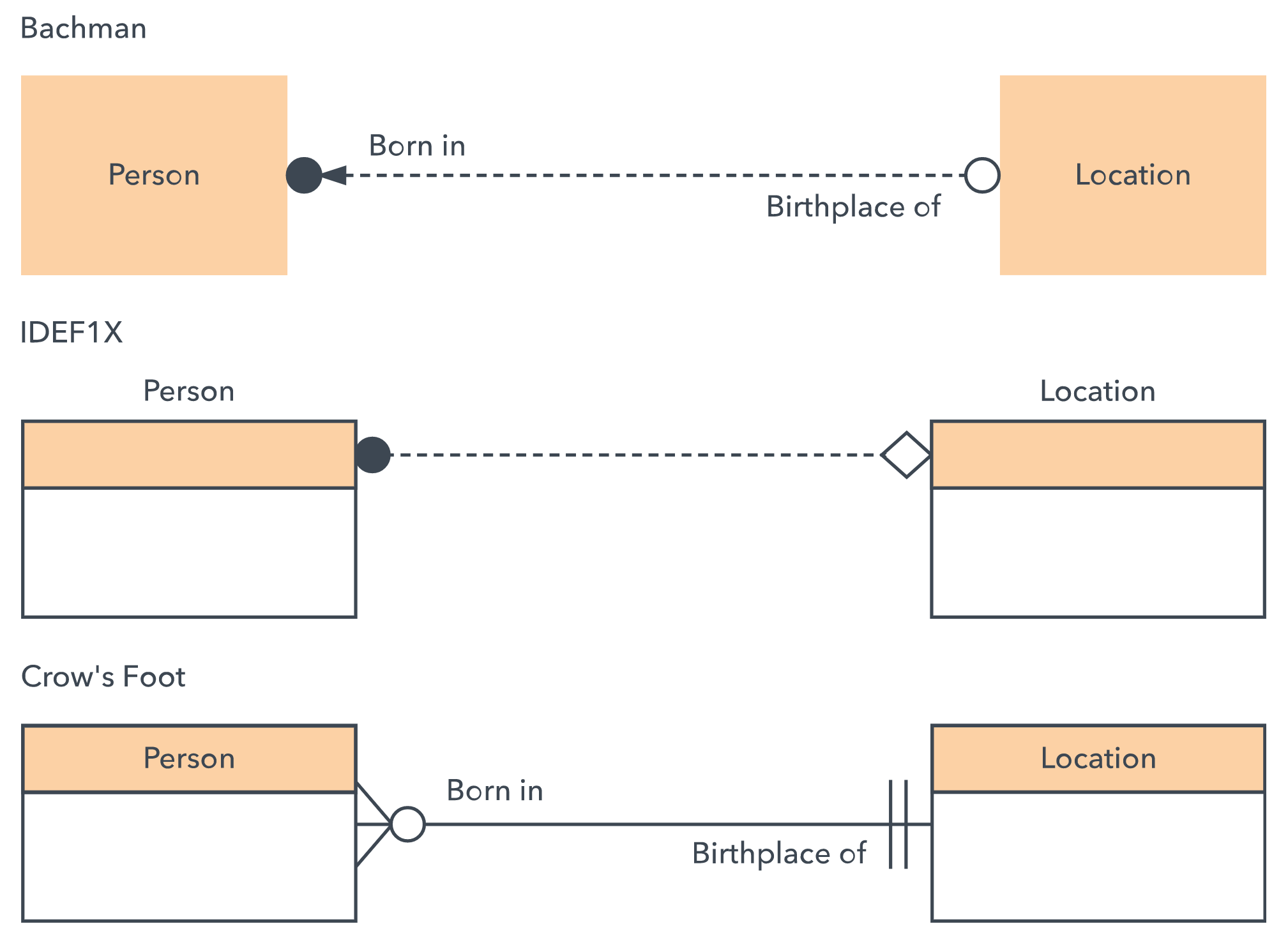
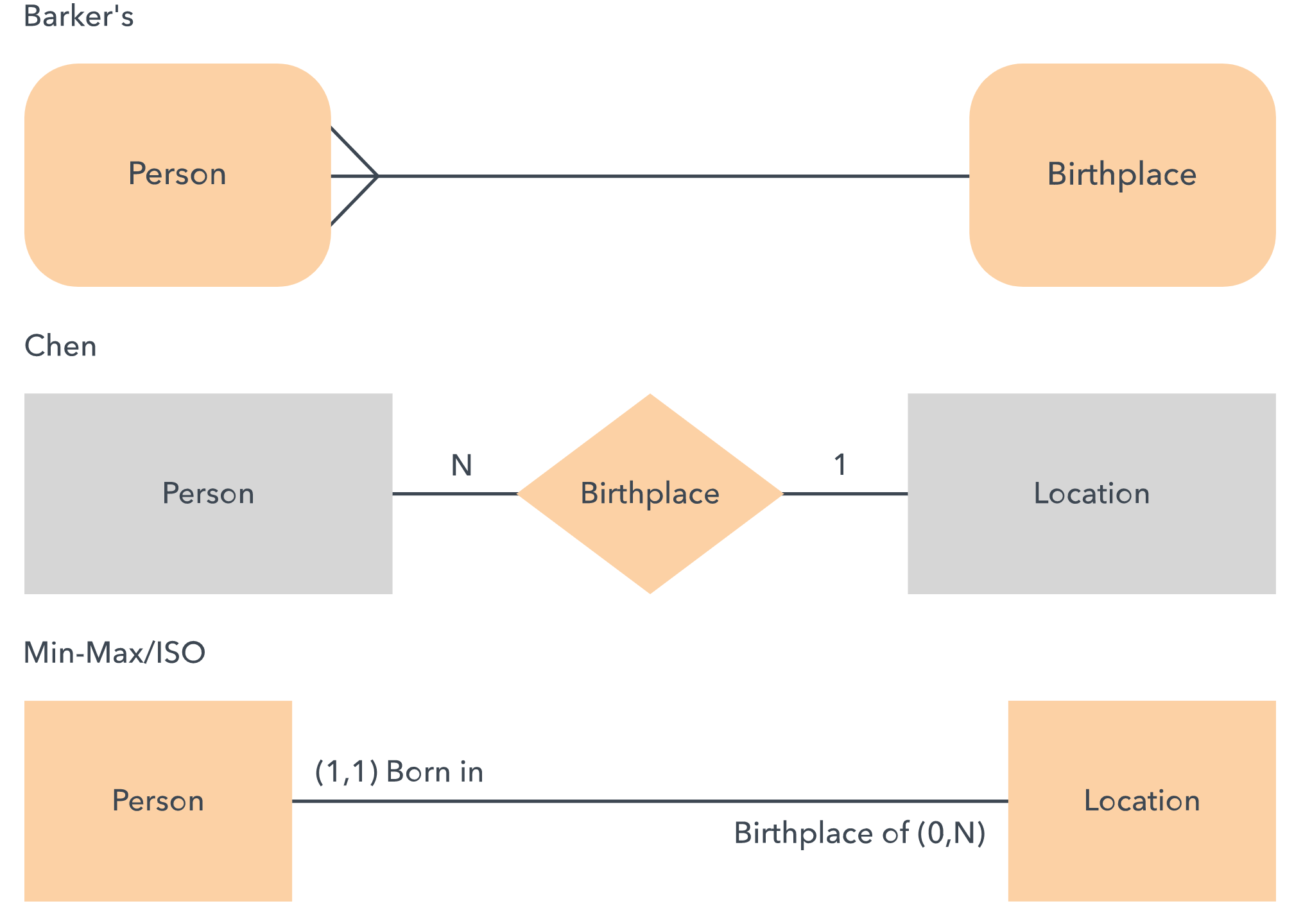
ERD symbols and notations
Chen notation style:
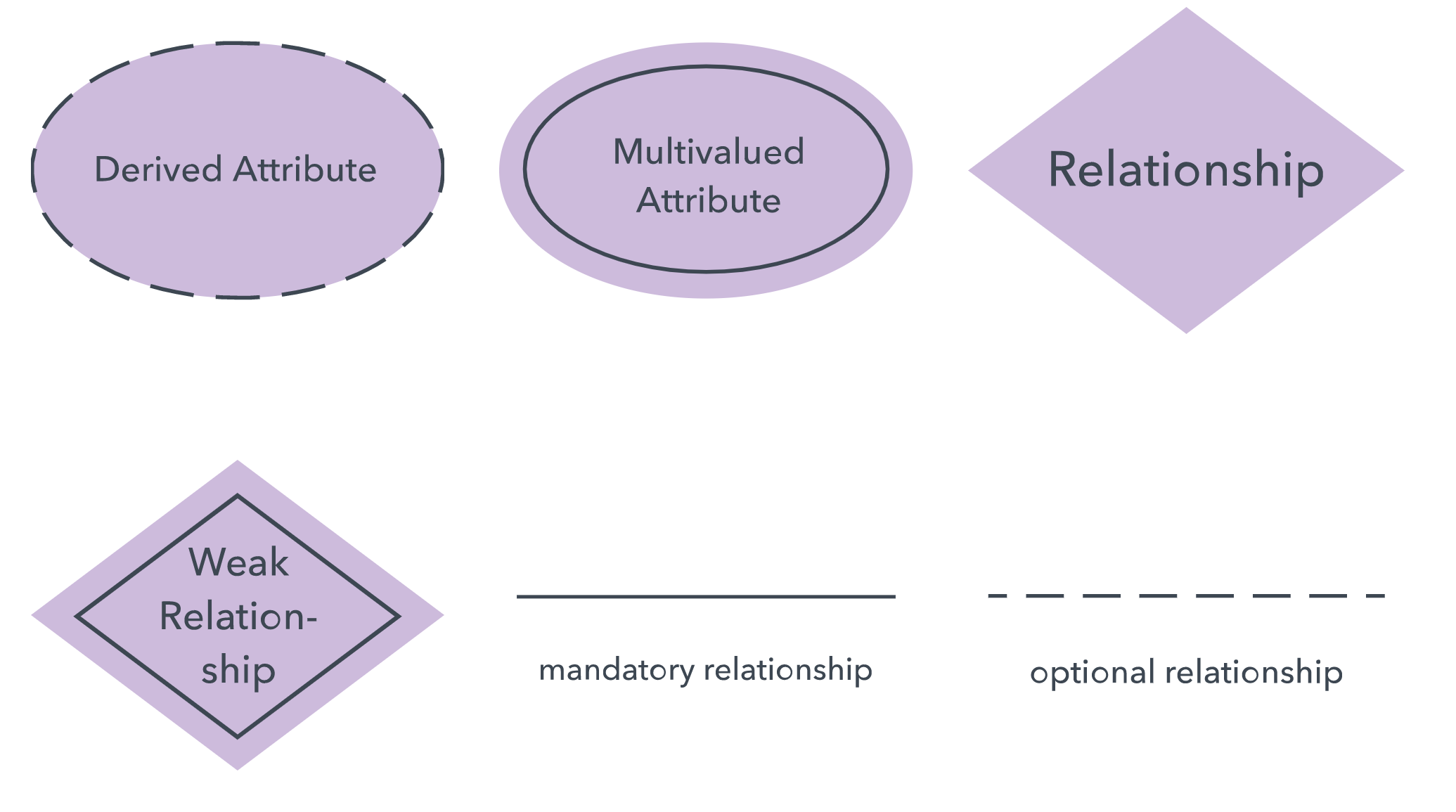
Crow's Foot/Martin/Information Engineering style:
IDEF1X style:
Barker style:
Examples: Following are examples of ERD diagrams made in each system.
Mapping natural language
ER components can be equated to parts of speech, as Peter Chen did. This shows how an ER Diagram compares to a grammar diagram:
Limitations of ER diagrams and models
How to draw ERD
SQL Database Setup
For the learning of SQL through this Skillzam Notes, Please Setup the Database and Tables, based on the below mentioned details:
company and create the five tables employee, customer, branch, empAssignment, vendor Create the Database & Tables
1. Create database "company"
CREATE DATABASE company;
2. Create Table "employee"
-- Table "employee"
CREATE TABLE employee (
emp_id INT PRIMARY KEY IDENTITY(10000,1),
firstname VARCHAR(32) NOT NULL,
lastname VARCHAR(32) NOT NULL,
doj DATE NOT NULL,
designation VARCHAR(32),
gender VARCHAR(6) NOT NULL,
salary INT,
lead_id INT,
branch_id INT
);
3. Create Table "branch"
-- Table "branch"
CREATE TABLE branch (
branch_id INT PRIMARY KEY,
branch_name VARCHAR(32) NOT NULL,
hob_id INT,
head_count INT,
FOREIGN KEY(hob_id)
REFERENCES employee(emp_id)
ON DELETE SET NULL
);
4. Add foreign key "branch_id"
-- Using ALTER, add foreign key "branch_id" in table "employee"
ALTER TABLE employee
ADD FOREIGN KEY(branch_id)
REFERENCES branch(branch_id)
ON DELETE SET NULL;
5. Create Table "customer"
-- Table "customer"
CREATE TABLE customer (
customer_id INT PRIMARY KEY,
customer_name VARCHAR(32) NOT NULL,
branch_id INT,
FOREIGN KEY(branch_id)
REFERENCES branch(branch_id)
ON DELETE SET NULL
);
6. Create Table "empAssignment""
-- Table "empAssignment"
CREATE TABLE empAssignment (
emp_id INT,
customer_id INT,
total_sales INT,
PRIMARY KEY(emp_id, customer_id),
FOREIGN KEY(emp_id) REFERENCES employee(emp_id) ON DELETE CASCADE,
FOREIGN KEY(customer_id) REFERENCES customer(customer_id) ON DELETE CASCADE
);
7. Create Table "vendor"
-- Table "vendor"
CREATE TABLE vendor (
branch_id INT,
vendor_name VARCHAR(32),
supply_type VARCHAR(32),
PRIMARY KEY(branch_id, vendor_name),
FOREIGN KEY(branch_id)
REFERENCES branch(branch_id)
ON DELETE CASCADE
);
Load tables with data
1. Insert Rows into table "employee"
-- Insert 10 Rows into table "employee"
INSERT INTO employee VALUES ('Rohit', 'Patil', '2000-10-20', 'CEO', 'MALE', 11000000, NULL, NULL);
INSERT INTO employee VALUES ('Fatima', 'Abdul', '2011-06-12', 'VP-IT', 'FEMALE', 5500000, 10000, NULL);
INSERT INTO employee VALUES('Sandeep', 'Shetty', '2020-09-11', 'Sr-Director', 'MALE', 4500000, 10001, NULL);
INSERT INTO employee VALUES('Mahesh', 'Dodamani', '2021-10-23', 'Sr-Director', 'MALE', 4000000, 10001, NULL);
INSERT INTO employee VALUES ('Pooja', 'Reddy', '2013-11-21', 'Sr-Developer', 'FEMALE', 3300000, 10002, NULL);
INSERT INTO employee VALUES ('John', 'Smith', '2014-09-12', 'Developer', 'MALE', 3000000, 10002, NULL);
INSERT INTO employee VALUES ('Sambit', 'Ramana', '2015-10-20', 'QA', 'MALE', 2500000, 10002, NULL);
INSERT INTO employee VALUES ('Mohammad', 'Irfan', '2011-06-12', 'Sr-Developer', 'MALE', 3500000, 10003, NULL);
INSERT INTO employee VALUES ('Varun', 'Naidu', '2016-10-20', 'Sr-Developer', 'MALE', 3600000, 10003, NULL);
INSERT INTO employee VALUES ('Ritu', 'Gupta', '2011-08-11', 'Developer', 'FEMALE', 2200000, 10003, NULL);
2. Insert Rows into table "branch"
-- Insert 3 Rows into table "branch"
INSERT INTO branch VALUES (101, 'HeadOffice', 10000, NULL);
INSERT INTO branch VALUES (102, 'Pune', 10002, NULL);
INSERT INTO branch VALUES (103, 'Hyderabad', 10003, NULL);
3. Update "employee" table & assign "branch_id"
-- Update "employee" table
UPDATE employee
SET branch_id = 101
WHERE emp_id IN (10000, 10001);
UPDATE employee
SET branch_id = 102
WHERE emp_id = 10002 OR lead_id = 10002;
UPDATE employee
SET branch_id = 103
WHERE emp_id = 10003 OR lead_id = 10003;
4. Insert Rows into table "vendor"
-- Insert 6 Rows into table "vendor"
INSERT INTO vendor VALUES(102, 'Kokuyo Camlin', 'Paper');
INSERT INTO vendor VALUES(102, 'Hindustan Pencils', 'Pencils');
INSERT INTO vendor VALUES(103, 'Kokuyo Camlin', 'Paper');
INSERT INTO vendor VALUES(102, 'Archies', 'Writing Pads');
INSERT INTO vendor VALUES(103, 'Navneet', 'Pens');
INSERT INTO vendor VALUES(103, 'Hindustan Pencils', 'Pencils');
5. Insert Rows into table "customer"
-- Insert 6 Rows into table "customer"
INSERT INTO customer VALUES(501, 'Cisco', 102);
INSERT INTO customer VALUES(502, 'FedEX', 102);
INSERT INTO customer VALUES(503, 'Walmart', 103);
INSERT INTO customer VALUES(504, 'AT&T', 103);
INSERT INTO customer VALUES(505, 'Apple', 102);
INSERT INTO customer VALUES(506, 'Meta', 103);
6. Insert Rows into table "empAssignment"
-- Insert 8 Rows into table "empAssignment"
INSERT INTO empAssignment VALUES(10002, 501, 55000);
INSERT INTO empAssignment VALUES(10004, 502, 267000);
INSERT INTO empAssignment VALUES(10005, 505, 22500);
INSERT INTO empAssignment VALUES(10006, 505, 5000);
INSERT INTO empAssignment VALUES(10003, 503, 15000);
INSERT INTO empAssignment VALUES(10007, 504, 12000);
INSERT INTO empAssignment VALUES(10008, 506, 33000);
INSERT INTO empAssignment VALUES(10009, 506, 26000);
SQL - Structured Query Language
History of SQL
Database Languages
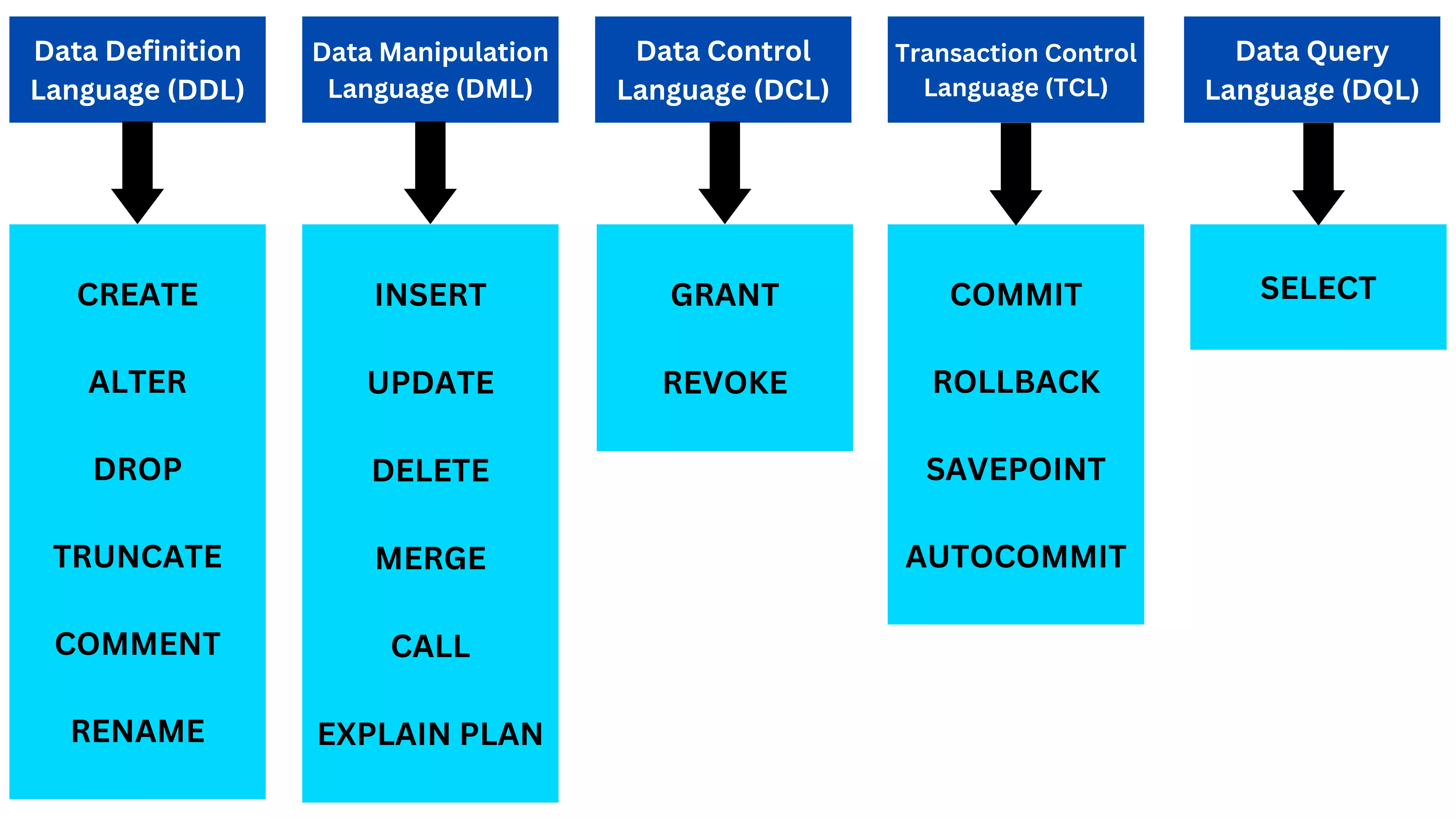
SQL can do many different things: create database tables, insert or change records, add indexes, retrieve information, and so on. So it can be useful to divide SQL into several sublanguages; this helps us wrap our heads around all the different operations that can be performed on an SQL database. These sublanguages are:
GRANT or REVOKE user access privileges.COMMIT transaction changes or to ROLLBACK transaction changes.SELECT used to get specific data from tables. Anatomy of SQL Query
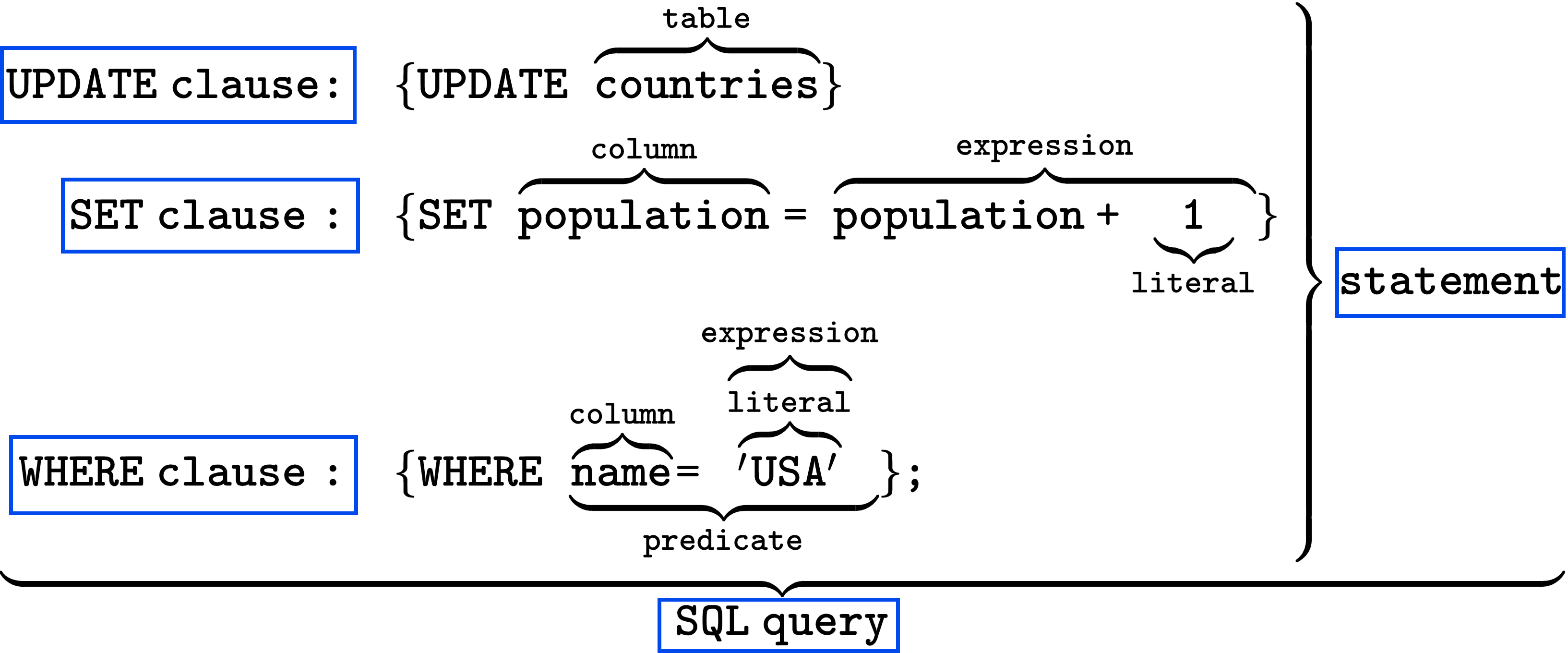
The SQL language is subdivided into several language elements, including:
SELECT, COUNT and YEAR ), or non-reserved (e.g. ASC,
DOMAIN and KEY).YEAR is specified as "YEAR". NOTE: In MySQL, double quotes are string literal delimiters by default instead.
SQL statements also include the semicolon (";") statement terminator. Though not required on every platform, it is defined as a standard part of the SQL grammar.
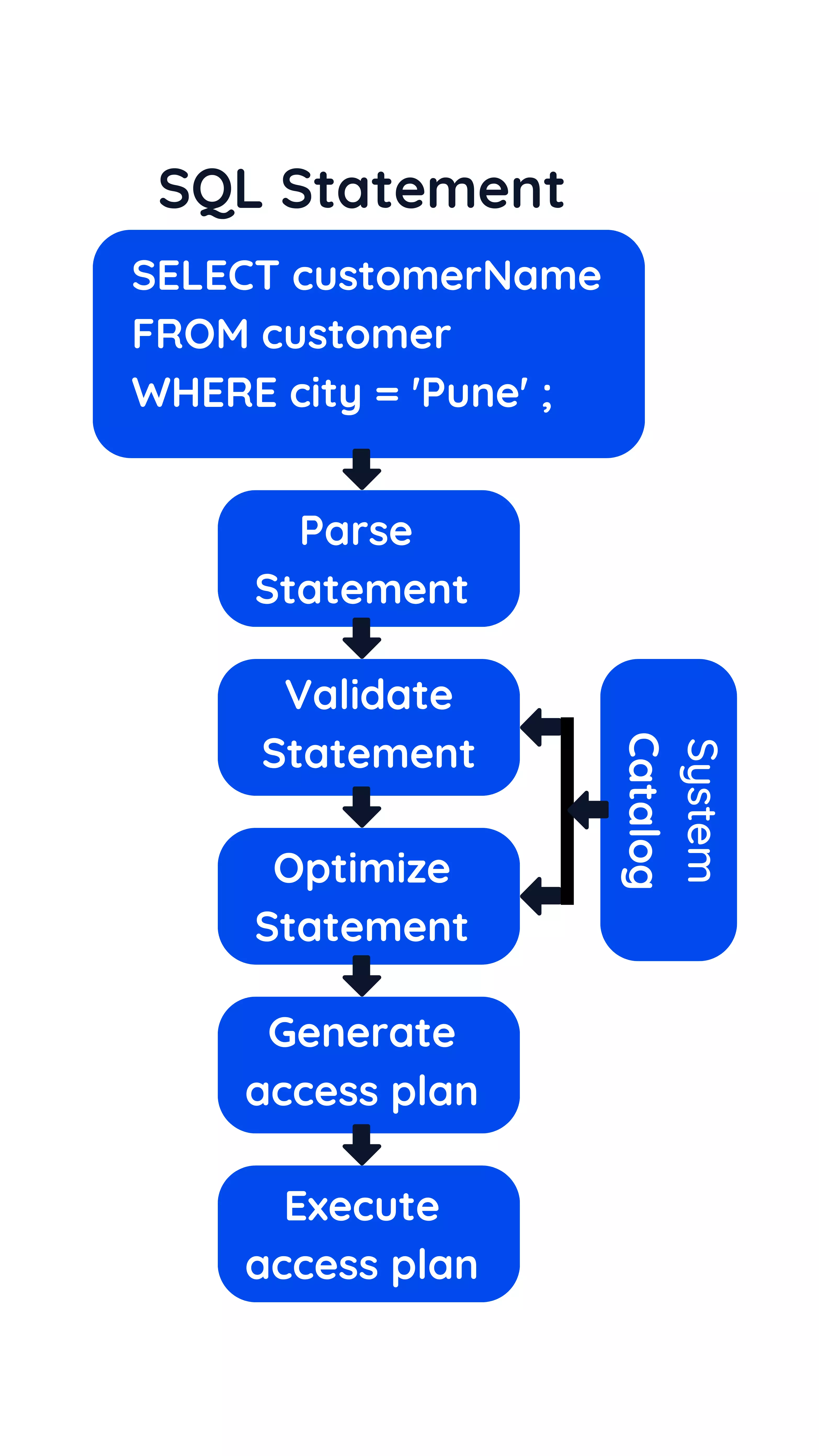
SQL Query Execution process
To process an SQL statement, a DBMS performs the following five steps:
The steps used to process an SQL statement vary in the amount of database access they require and the amount of time they take. Parsing an SQL statement does not require access to the database and can be done very quickly. Optimization, on the other hand, is a very CPU-intensive process and requires access to the system catalog. For a complex, multitable query, the optimizer may explore thousands of different ways of carrying out the same query. However, the cost of executing the query inefficiently is usually so high that the time spent in optimization is more than regained in increased query execution speed. This is even more significant if the same optimized access plan can be used over and over to perform repetitive queries.
Comments in SQL
Standard SQL allows two formats for comments:
-- comment which is ended by the first newline/* comment */ which can span multiple lines.
-- Comment in SQL
/*
This is a
multi-line comment in SQL
*/
Define & Modify Data
1. Create Database
CREATE DATABASE statement is used to create a new SQL database.SHOW DATABASES; EXAMPLE:Below example will create the database named company
CREATE DATABASE company;
2. Create Table
CREATE TABLE statement is used to create a new table in a database. create "employee" table
-- Create "employee" entity(table) with nine attributes(columns)
CREATE TABLE employee (
emp_id INT PRIMARY KEY IDENTITY(10000,1),
firstname VARCHAR(32) NOT NULL,
lastname VARCHAR(32) NOT NULL,
doj DATE NOT NULL,
designation VARCHAR(32),
gender VARCHAR(6) NOT NULL,
salary INT,
lead_id INT,
branch_id INT
);
EXAMPLE: In the above example, the employee table contains nine columns:
IDENTITY(10000,1) instructs SQL Server to automatically generate integer numbers for the column starting from 10000 and increasing by one for each new row.VARCHAR type. These columns can store up to 32 characters.DATE in format YYYYMMDD. This column represents the date of joining of an employee.VARCHAR type. This column can store up to 32 characters and can accept the NULLVARCHAR type. This column can store up to 6 characters and can not accept the NULLINT type. 3. Alter Table
EXAMPLE: Below example will alter the table named employee by adding a foreign key:
FOREIGN KEY constraint.branch is a parent table that is the table to which the foreign key constraint references.employee table is called the child table that is the table to which the foreign key branch_id constraint is applied.ON DELETE SET NULL clause, it means that when the referenced record in the parent table is deleted, the corresponding foreign key value in the child table will be set to NULL. This can be useful when you want to allow a child record to exist without a corresponding parent record, or when you want to break a relationship between two tables without deleting any data.
-- Alter table "employee" by adding a foreign key constraint
ALTER TABLE employee
ADD FOREIGN KEY(branch_id)
REFERENCES branch(branch_id)
ON DELETE SET NULL;
4. Insert into table
INSERT statement
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);
VALUES keyword is used to specify the values that will be inserted into each column. INSERT INTO statement can also be used with subqueries to insert data into a table based on the results of a query, and it can be used to insert multiple records at once by specifying multiple sets of values in the VALUES clause.EXAMPLE: Add table rows for both tables "employee" and "branch".
-- Insert row into table "employee"
INSERT INTO employee
VALUES ('Rohit', 'Patil', '2000-10-20', 'CEO', 'MALE', 11000000, NULL, NULL);
-- Insert three rows in table "branch" using single INSERT statement
INSERT INTO branch
VALUES
(101, 'HeadOffice', 10000, NULL),
(102, 'Pune', 10002, NULL),
(103, 'Hyderabad', 10003, NULL);
5. Update Table
UPDATE statement in SQL is used to modify existing data in a table. UPDATE statement allows you to change the values in one or more columns of one or more rows in a table.UPDATE statement can also be used with subqueries to update data in a table based on the results of a query, and it can be used to update multiple columns at once by specifying multiple column-value pairs in the SET clause.
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
SET keyword is used to specify the new values for the columns, and "value1, value2, ..." are the new values for the columns. WHERE clause is optional and is used to specify which rows to update. If the WHERE clause is not used, all rows in the table will be updated.EXAMPLE: In the below example we will update rows based on condition.
-- Update the "employee" table & assign "branch_id"
UPDATE employee
SET branch_id = 102
WHERE emp_id = 10002 OR lead_id = 10002;
In the above UPDATE statement example, query will update the branch_id (branch ID) column of all rows in the "employee" table where the "emp_id" is 10002 OR "lead_id" is 10002
Querying data
SELECT statement
SELECT statement in SQL is used to retrieve data from one or more tables in a database. It allows you to specify which columns to retrieve, which table or tables to retrieve them from, and any conditions that must be met to retrieve the data.SELECT statement can also be used with various functions, such as SUM, AVG, MAX, and MIN, to perform calculations on the data, and it can be used with subqueries to retrieve data based on the results of a query.SYNTAX:
In the below syntax, "column1, column2, column3 ..." are the names of the columns to retrieve, and "table_name" is the name of the table to retrieve them from. The FROM keyword is used to specify the table or tables to retrieve the data from.
SELECT column1, column2, column3 ...
FROM table_name;
EXAMPLE [1]:
Below example will retrieve all the rows & column data from the table "branch".
-- Select all rows from the table "branch"
SELECT * FROM branch;
| branch_id | branch_name | hob_id | head_count |
|---|---|---|---|
| 101 | HeadOffice | 10000 | NULL |
| 102 | Pune | 10002 | NULL |
| 103 | Hyderabad | 10003 | NULL |
EXAMPLE [2]:
Below example will retrieve some columns' data from the table "branch".
-- Select branch_id and branch_name columns from table "branch"
SELECT branch_id, branch_name
FROM branch;
| branch_id | branch_name |
|---|---|
| 101 | HeadOffice |
| 102 | Pune |
| 103 | Hyderabad |
EXAMPLE [3]:
SELECT DISTINCT statement is used to return only distinct values. In the below example, the SQL statement selects only the DISTINCT values from the "supply_type" column in the "vendor" table:
-- select DISTINCT "supply_type" column values from "vendor" table
SELECT DISTINCT supply_type
FROM vendor;
| supply_type |
|---|
| Paper |
| Pencils |
| Pens |
| Writing Pads |
EXAMPLE [4]:
COUNT(DISTINCT supply_type) lists the number of different (distinct) "supply_type" in the "vendor" table:
-- list number of different "supply_type" values from "vendor" table
SELECT COUNT(DISTINCT supply_type)
FROM vendor;
4
Sorting Data
ORDER BY clause in a SELECT statement. SELECT statement to query data from a table, the order of rows in the result set is not guaranteed. It means that DBMS can return a result set with an unspecified order of rows.ORDER BY Clause
ORDER BY clause is used to sort the result-set in ascending or descending order.ORDER BY clause sorts the rows in ascending order ( ASC ).DESC. SYNTAX:
SELECT column1, column2, ...
FROM table_name
ORDER BY column1 [ASC|DESC], column2 [ASC|DESC], ...;
Sorting by one column in ascending order
In the below example, because we did not specify ASC or DESC, the ORDER BY clause used ASC by default.
-- Sorting by one column
SELECT * FROM vendor
ORDER BY vendor_name;
| branch_id | vendor_name | supply_type |
|---|---|---|
| 102 | Archies | Writing Pads |
| 102 | Hindustan Pencils | Pencils |
| 103 | Hindustan Pencils | Pencils |
| 103 | Kokuyo Camlin | Paper |
| 102 | Kokuyo Camlin | Paper |
| 103 | Navneet | Pens |
Sorting by multiple columns and different orders
In the below example, sorts the vendor table by the column vendor_name in ascending order ( ASC ) and then sorts the sorted result set by the column branch_id in descending order ( DESC ).
-- Sorting by multiple columns
SELECT * FROM vendor
ORDER BY vendor_name ASC, branch_id DESC;
| branch_id | vendor_name | supply_type |
|---|---|---|
| 102 | Archies | Writing Pads |
| 103 | Hindustan Pencils | Pencils |
| 102 | Hindustan Pencils | Pencils |
| 103 | Kokuyo Camlin | Paper |
| 102 | Kokuyo Camlin | Paper |
| 103 | Navneet | Pens |
SQL Operators
SQL operators are special symbols or keywords used in SQL statements to perform arithmetic operations, comparison operations, logical operations, and string operations.
SQL operators are used in SQL statements such as SELECT, INSERT, UPDATE, and DELETE. By using operators, you can create complex queries and manipulate data in a variety of ways.
There are several types of operators in SQL, including:
AND, OR, and NOT. The AND operator returns true if both conditions are true, the OR operator returns true if either condition is true, and the NOT operator negates the condition.|| and LIKE. The concatenation operator is used to combine two or more strings into a single string, while the LIKE operator is used for pattern matching.SELECT statements. The set operators include UNION, UNION ALL, INTERSECT, and EXCEPT.AND Operator
AND is a logical operator that allows you to combine two Boolean expressions.TRUE only when both expressions evaluate to TRUE. SYNTAX:
WHERE clause is used to filter the results based on one or more conditions. AND operator.
SELECT column1, column2, ...
FROM table_name
WHERE condition1 AND condition2 AND ...;
EXAMPLE:
In the below example, the SELECT statement with WHERE clause retrieves all rows with the column branch_id value is 102 AND the column supply_type value is Pencils from the vendor table.
-- AND Operator example
SELECT * FROM vendor
WHERE branch_id = 102 AND supply_type = 'Pencils';
| branch_id | vendor_name | supply_type |
|---|---|---|
| 102 | Hindustan Pencils | Pencils |
OR Operator
OR is a logical operator that allows you to combine two or more conditions in a WHERE clause.TRUE, if any of the conditions are TRUE. SYNTAX:
WHERE clause is used to filter the results based on one or more conditions. OR operator.
SELECT column1, column2, ...
FROM table_name
WHERE condition1 OR condition2 OR ...;
EXAMPLE:
In the below example, the SELECT statement with WHERE clause retrieves all rows with the column branch_id value is 102 OR the column supply_type value is Pencils from the vendor table.
-- OR Operator example
SELECT * FROM vendor
WHERE branch_id = 102 OR supply_type = 'Pencils';
| branch_id | vendor_name | supply_type |
|---|---|---|
| 102 | Archies | Writing Pads |
| 102 | Hindustan Pencils | Pencils |
| 102 | Kokuyo Camlin | Paper |
| 103 | Hindustan Pencils | Pencils |
NOT Operator
NOT is a logical operator that allows you to negate a condition in a WHERE clause.NOT operator is used to negate a single condition and returns TRUE if the condition is FALSE.SYNTAX:
WHERE clause is used to filter the results based on a single condition. NOT operator, which negates it.
SELECT column1, column2, ...
FROM table_name
WHERE NOT condition;
EXAMPLE:
In the below example, the query will retrieve all rows the "vendor" table and filter the results based on a single condition: "NOT branch_id = 103". The NOT operator negates the condition "branch_id = 103", so only rows with a branch ID of other than 103 be returned.
-- NOT Operator example
SELECT * FROM vendor
WHERE NOT branch_id = 103;
| branch_id | vendor_name | supply_type |
|---|---|---|
| 102 | Archies | Writing Pads |
| 102 | Hindustan Pencils | Pencils |
| 102 | Kokuyo Camlin | Paper |
IN Operato
IN is a logical operator that allows you to specify multiple values in a WHERE clause.IN operator is used to match a value against a list of values and returns TRUE, if the value matches any of the values in the list. SYNTAX:
WHERE clause is used to filter the results based on a single condition.IN operator, followed by a list of values in parentheses ( ).
SELECT column1, column2, ...
FROM table_name
WHERE column_name IN (value1, value2, ...);
EXAMPLE:
In the below example, the query will retrieve all rows, from the "vendor" table and filter the results based on a single condition: "supply_type IN ('Pencils','Pens')".
The IN operator matches the supply type column against the list of values 'Pencils', 'Pens', so only rows with supply type matching those values will be returned.
-- IN Operator example
SELECT * FROM vendor
WHERE supply_type IN ('Pencils','Pens');
| branch_id | vendor_name | supply_type |
|---|---|---|
| 102 | Hindustan Pencils | Pencils |
| 103 | Hindustan Pencils | Pencils |
| 103 | Navneet | Pens |
BETWEEN Operator
BETWEEN is used to filter results based on a range of values.SYNTAX:
WHERE clause is used to filter the results based on a single condition.BETWEEN operator followed by two values, value1 and value2, separated by the AND keyword.
SELECT column1, column2, ...
FROM table_name
WHERE column_name BETWEEN value1 AND value2;
EXAMPLE:
In the below example, the query will retrieve the firstname, lastname and salary columns from the "employee" table and filter the results based on a single condition: "salary BETWEEN 4500000 AND 11000000".
The BETWEEN operator matches the salary column against the range of salary between 4500000, and 11000000, inclusive, so only rows with salary falling within that range will be returned.
-- BETWEEN Operator example
SELECT firstname, lastname, salary
FROM employee
WHERE salary BETWEEN 4500000 AND 11000000;
| firstname | lastname | salary |
|---|---|---|
| Rohit | Patil | 11000000 |
| Fatima | Abdul | 5500000 |
| Sandeep | Shetty | 4500000 |
LIKE Operator
LIKE is used to match a string pattern in a column value.SYNTAX:
WHERE clause is used to filter the results based on a single condition.LIKE operator followed by a string pattern to match against the values in the specified column.
SELECT column1, column2, ...
FROM table_name
WHERE column_name LIKE pattern;
EXAMPLE:
In the below example, the query will retrieve all rows, from the "vendor" table and filter the results based on a single condition: supply_type LIKE 'Pen%'.
The "%" wildcard character matches any number of characters after the "Pen" string, so only rows with supply type starting in "Pen" will be returned.
-- LIKE Operator example
SELECT * FROM vendor
WHERE supply_type LIKE 'Pen%';
| branch_id | vendor_name | supply_type |
|---|---|---|
| 102 | Hindustan Pencils | Pencils |
| 103 | Hindustan Pencils | Pencils |
| 103 | Navneet | Pens |
IS NULL Operator
IS NULL operator is used to check, if a column value is NULL or not.TRUE if the value is NULL, and FALSE, if it is not NULL.SYNTAX:
WHERE clause is used to filter the results based on a single condition.IS NULL operator to check, if the specified column value is NULL.
SELECT column1, column2, ...
FROM table_name
WHERE column_name IS NULL;
EXAMPLE:
In the below example, the query will retrieve the firstname, lastname and lead_id columns from the "employee" table and filter the results based on a single condition: "lead_id IS NULL".
The query will return only the rows where the "lead_id" column is null, indicating that the employee is the CEO and has no reporting manager.
-- IS NULL Operator example
SELECT firstname, lastname, lead_id
FROM employee
WHERE lead_id IS NULL;
| firstname | lastname | lead_id |
|---|---|---|
| Rohit | Patil | NULL |
IS NOT NULL Operator
IS NOT NULL operator is used to check, if a column value is not null. TRUE, if the value is not null, and FALSE if it is null.SYNTAX:
WHERE clause is used to filter the results based on a single condition.IS NOT NULL operator to check, if the specified column value is not null.
SELECT column1, column2, ...
FROM table_name
WHERE column_name IS NOT NULL;
EXAMPLE:
In the below example, the query will retrieve the firstname, lastname and lead_id columns from the "employee" table and filter the results based on a single condition: "lead_id IS NOT NULL".
The query will return only the rows where the "lead_id" column is not null, indicating that the employees have a lead reporting manager.
-- IS NULL Operator example
SELECT firstname, lastname, lead_id
FROM employee
WHERE lead_id IS NULL;
| firstname | lastname | lead_id |
|---|---|---|
| Fatima | Abdul | 10000 |
| Sandeep | Shetty | 10001 |
| Mahesh | Dodamani | 10001 |
| Pooja | Reddy | 10002 |
| John | Smith | 10002 |
| Sambit | Ramana | 10002 |
| Mohammad | Irfan | 10003 |
| Varun | Naidu | 10003 |
| Ritu | Gupta | 10003 |
Filtering Data
Filtering data is a common task in SQL, and it can be accomplished using the WHERE clause in a SELECT statement.
WHERE Clause
WHERE clause allows you to specify conditions that filter the rows that are returned by a query.WHERE clause is not only used in SELECT statements, it is also used in UPDATE, DELETE, etc.SYNTAX:
LIKE operator to perform pattern matching on string values.IN operator to match a value against a list of possible values.
SELECT column1, column2, ...
FROM table_name
WHERE condition1 [AND|OR] condition2 [AND|OR] ...;
WHERE Clause : Filtering rows by using a equality ( = )
In the below example, the SELECT statement with WHERE clause retrieves all rows with the column branch_id value is 102 from the vendor table.
-- Filtering rows using WHERE & equality (=)
SELECT * FROM vendor
WHERE branch_id = 102;
| branch_id | vendor_name | supply_type |
|---|---|---|
| 102 | Archies | Writing Pads |
| 102 | Hindustan Pencils | Pencils |
| 102 | Kokuyo Camlin | Paper |
WHERE Clause : Filtering rows that meet two conditions
In the below example, the SELECT statement with WHERE clause retrieves all rows with the column branch_id value is 102 AND the column supply_type value is Pencils from the vendor table.
-- Filtering rows with two conditions
SELECT * FROM vendor
WHERE branch_id = 102 AND supply_type = 'Pencils';
| branch_id | vendor_name | supply_type |
|---|---|---|
| 102 | Hindustan Pencils | Pencils |
Reserved keywords in SQL
Below list includes SQL reserved words, as the SQL:2016 specifies and some RDBMSs have added :
| SQL:2016 | IBM Db2 | Mimer SQ | MySQL | Oracle Database | PostgreSQL | Microsoft SQL Server | Teradata | |
|---|---|---|---|---|---|---|---|---|
| ABORT | — | — | — | — | — | — | — | Teradata |
| ABORTSESSION | — | — | — | — | — | — | — | Teradata |
| ABS | SQL-2016 | — | — | — | — | — | — | Teradata |
| ABSENT | SQL-2016 | — | — | — | — | — | — | — |
| ABSOLUTE | — | — | — | — | — | — | — | Teradata |
| ACCESS | — | — | — | — | Oracle | — | — | — |
| ACCESSIBLE | — | — | — | MySQL | — | — | — | — |
| ACCESS_LOCK | — | — | — | — | — | — | — | Teradata |
| ACCOUNT | — | — | — | — | — | — | — | Teradata |
| ACOS | SQL-2016 | — | — | — | — | — | — | Teradata |
| ACOSH | — | — | — | — | — | — | — | Teradata |
| ACTION | — | — | — | — | — | — | — | Teradata |
| ADD | — | DB2 | — | MySQL | Oracle | — | SQL Server | Teradata |
| ADD_MONTHS | — | — | — | — | — | — | — | Teradata |
| ADMIN | — | — | — | — | — | — | — | Teradata |
| AFTER | — | DB2 | — | — | — | — | — | Teradata |
| AGGREGATE | — | — | — | — | — | — | — | Teradata |
| ALIAS | — | — | — | — | — | — | — | Teradata |
| ALL | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| ALLOCATE | SQL-2016 | DB2 | Mimer | — | — | — | — | Teradata |
| ALLOW | — | DB2 | — | — | — | — | — | — |
| ALTER | SQL-2016 | — | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| ALTERAND | — | DB2 | — | — | — | — | — | — |
| AMP | — | — | — | — | — | — | — | Teradata |
| ANALYSE | — | — | — | — | — | PostgreSQL | — | — |
| ANALYZE | — | — | — | MySQL | — | PostgreSQL | — | — |
| AND | SQL-2016 | — | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| ANSIDATE | — | — | — | — | — | — | — | Teradata |
| ANY | SQL-2016 | DB2 | Mimer | — | Oracle | PostgreSQL | SQL Server | Teradata |
| ARE | SQL-2016 | — | — | — | — | — | — | Teradata |
| ARRAY | SQL-2016 | DB2 | — | — | — | PostgreSQL | — | Teradata |
| ARRAY_AGG | SQL-2016 | — | — | — | — | — | — | — |
| ARRAY_EXISTS | — | DB2 | — | — | — | — | — | — |
| ARRAY_MAX_CARDINALITY | SQL-2016 | — | — | — | — | — | — | — |
| AS | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| ASC | — | — | — | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| ASENSITIVE | SQL-2016 | DB2 | — | MySQL | — | — | — | — |
| ASIN | SQL-2016 | — | — | — | — | — | — | Teradata |
| ASINH | — | — | — | — | — | — | — | Teradata |
| ASSERTION | — | — | — | — | — | — | — | Teradata |
| ASSOCIATE | — | DB2 | — | — | — | — | — | — |
| ASUTIME | — | DB2 | — | — | — | — | — | — |
| ASYMMETRIC | SQL-2016 | — | Mimer | — | — | PostgreSQL | — | — |
| AT | SQL-2016 | DB2 | Mimer | — | — | — | — | Teradata |
| ATAN | SQL-2016 | — | — | — | — | — | — | Teradata |
| ATAN2 | — | — | — | — | — | — | — | Teradata |
| ATANH | — | — | — | — | — | — | — | Teradata |
| ATOMIC | SQL-2016 | — | Mimer | — | — | — | — | Teradata |
| AUDIT | — | DB2 | — | — | Oracle | — | — | — |
| AUTHORIZATION | SQL-2016 | — | Mimer | — | — | PostgreSQL | SQL Server | Teradata |
| AUX | — | DB2 | — | — | — | — | — | — |
| AUXILIARY | — | DB2 | — | — | — | — | — | — |
| AVE | — | — | — | — | — | — | — | Teradata |
| AVERAGE | — | — | — | — | — | — | — | Teradata |
| AVG | SQL-2016 | — | — | — | — | — | — | Teradata |
| BACKUP | — | — | — | — | — | — | SQL Server | — |
| BEFORE | — | DB2 | — | MySQL | — | — | — | Teradata |
| BEGIN | SQL-2016 | DB2 | Mimer | — | — | — | SQL Server | Teradata |
| BEGIN_FRAME | SQL-2016 | — | — | — | — | — | — | — |
| BEGIN_PARTITION | SQL-2016 | — | — | — | — | — | — | — |
| BETWEEN | SQL-2016 | DB2 | Mimer | MySQL | Oracle | — | SQL Server | Teradata |
| BIGINT | SQL-2016 | — | — | MySQL | — | — | — | — |
| BINARY | SQL-2016 | — | — | MySQL | — | PostgreSQL | — | Teradata |
| BIT | — | — | — | — | — | — | — | Teradata |
| BLOB | SQL-2016 | — | — | MySQL | — | — | — | Teradata |
| BOOLEAN | SQL-2016 | — | — | — | — | — | — | Teradata |
| BOTH | SQL-2016 | — | Mimer | MySQL | — | PostgreSQL | — | Teradata |
| BREADTH | — | — | — | — | — | — | — | Teradata |
| BREAK | — | — | — | — | — | — | SQL Server | — |
| BROWSE | — | — | — | — | — | — | SQL Server | — |
| BT | — | — | — | — | — | — | — | Teradata |
| BUFFERPOOL | — | DB2 | — | — | — | — | — | — |
| BULK | — | — | — | — | — | — | SQL Server | — |
| BUT | — | — | — | — | — | — | — | Teradata |
| BY | SQL-2016 | DB2 | Mimer | MySQL | Oracle | — | SQL Server | Teradata |
| BYTE | — | — | — | — | — | — | — | Teradata |
| BYTEINT | — | — | — | — | — | — | — | Teradata |
| BYTES | — | — | — | — | — | — | — | Teradata |
| CALL | SQL-2016 | DB2 | Mimer | MySQL | — | — | — | Teradata |
| CALLED | SQL-2016 | — | Mimer | — | — | — | — | — |
| CAPTURE | — | DB2 | — | — | — | — | — | — |
| CARDINALITY | SQL-2016 | — | — | — | — | — | — | — |
| CASCADE | — | — | — | MySQL | — | — | SQL Server | Teradata |
| CASCADED | SQL-2016 | DB2 | — | — | — | — | — | Teradata |
| CASE | SQL-2016 | DB2 | Mimer | MySQL | — | PostgreSQL | SQL Server | Teradata |
| CASESPECIFIC | — | — | — | — | — | — | — | Teradata |
| CASE_N | — | — | — | — | — | — | — | Teradata |
| CAST | SQL-2016 | DB2 | Mimer | — | — | PostgreSQL | — | Teradata |
| CATALOG | — | — | — | — | — | — | — | Teradata |
| CCSID | — | DB2 | — | — | — | — | — | — |
| CD | — | — | — | — | — | — | — | Teradata |
| CEIL | SQL-2016 | — | — | — | — | — | — | — |
| CEILING | SQL-2016 | — | — | — | — | — | — | — |
| CHANGE | — | — | — | MySQL | — | — | — | — |
| CHAR | SQL-2016 | DB2 | — | MySQL | Oracle | — | — | Teradata |
| CHAR2HEXINT | — | — | — | — | — | — | — | Teradata |
| CHARACTER | SQL-2016 | DB2 | — | MySQL | — | — | — | Teradata |
| CHARACTERS | — | — | — | — | — | — | — | Teradata |
| CHARACTER_LENGTH | SQL-2016 | — | — | — | — | — | — | Teradata |
| CHARS | — | — | — | — | — | — | — | Teradata |
| CHAR_LENGTH | SQL-2016 | — | — | — | — | — | — | Teradata |
| CHECK | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| CHECKPOINT | — | — | — | — | — | — | SQL Server | Teradata |
| CLASS | — | — | — | — | — | — | — | Teradata |
| CLASSIFIER | SQL-2016 | — | — | — | — | — | — | — |
| CLOB | SQL-2016 | — | — | — | — | — | — | Teradata |
| CLONE | — | DB2 | — | — | — | — | — | — |
| CLOSE | SQL-2016 | DB2 | Mimer | — | — | — | SQL Server | Teradata |
| CLUSTER | — | DB2 | — | — | Oracle | — | — | Teradata |
| CLUSTERED | — | — | — | — | — | — | SQL Server | — |
| CM | — | — | — | — | — | — | — | Teradata |
| COALESCE | SQL-2016 | — | — | — | — | — | SQL Server | Teradata |
| COLLATE | SQL-2016 | — | Mimer | MySQL | — | PostgreSQL | SQL Server | Teradata |
| COLLATION | — | — | — | — | — | PostgreSQL | — | Teradata |
| COLLECT | SQL-2016 | — | — | — | — | — | — | Teradata |
| COLLECTION | — | DB2 | — | — | — | — | — | — |
| COLLID | — | DB2 | — | — | — | — | — | — |
| COLUMN | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| COLUMN_VALUE | — | — | — | — | Oracle | — | — | — |
| COMMENT | — | DB2 | — | — | Oracle | — | — | Teradata |
| COMMIT | SQL-2016 | DB2 | Mimer | — | — | — | SQL Server | Teradata |
| COMPLETION | — | — | — | — | — | — | — | Teradata |
| COMPRESS | — | — | — | — | Oracle | — | — | Teradata |
| COMPUTE | — | — | — | — | — | — | SQL Server | — |
| CONCAT | — | DB2 | — | — | — | — | — | — |
| CONCURRENTLY | — | — | — | — | — | PostgreSQL | — | — |
| CONDITION | SQL-2016 | DB2 | Mimer | MySQL | — | — | — | — |
| CONNECT | SQL-2016 | DB2 | Mimer | — | Oracle | — | — | Teradata |
| CONNECTION | — | DB2 | — | — | — | — | — | Teradata |
| CONSTRAINT | SQL-2016 | DB2 | Mimer | MySQL | — | PostgreSQL | SQL Server | Teradata |
| CONSTRAINTS | — | — | — | — | — | — | — | Teradata |
| CONSTRUCTOR | — | — | — | — | — | — | — | Teradata |
| CONTAINS | SQL-2016 | DB2 | — | — | — | — | SQL Server | — |
| CONTAINSTABLE | — | — | — | — | — | — | SQL Server | — |
| CONTENT | — | DB2 | — | — | — | — | — | — |
| CONTINUE | — | DB2 | — | MySQL | — | — | SQL Server | Teradata |
| CONVERT | SQL-2016 | — | — | MySQL | — | — | SQL Server | — |
| CONVERT_TABLE_HEADER | — | — | — | — | — | — | — | Teradata |
| COPY | SQL-2016 | — | — | — | — | — | — | — |
| CORR | SQL-2016 | — | — | — | — | — | — | Teradata |
| CORRESPONDING | SQL-2016 | — | Mimer | — | — | — | — | Teradata |
| COS | SQL-2016 | — | — | — | — | — | — | Teradata |
| COSH | SQL-2016 | — | — | — | — | — | — | Teradata |
| COUNT | SQL-2016 | — | — | — | — | — | — | Teradata |
| COVAR_POP | SQL-2016 | — | — | — | — | — | — | Teradata |
| COVAR_SAMP | SQL-2016 | — | — | — | — | — | — | Teradata |
| CREATE | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| CROSS | SQL-2016 | — | Mimer | MySQL | — | PostgreSQL | SQL Server | Teradata |
| CS | — | — | — | — | — | — | — | Teradata |
| CSUM | — | — | — | — | — | — | — | Teradata |
| CT | — | — | — | — | — | — | — | Teradata |
| CUBE | SQL-2016 | DB2 | — | MySQL | — | — | — | Teradata |
| CUME_DIST | SQL-2016 | — | — | MySQL | — | — | — | — |
| CURRENT | SQL-2016 | DB2 | Mimer | — | Oracle | — | SQL Server | Teradata |
| CURRENT_CATALOG | SQL-2016 | — | — | — | — | PostgreSQL | — | — |
| CURRENT_DATE | SQL-2016 | DB2 | Mimer | MySQL | — | PostgreSQL | SQL Server | Teradata |
| CURRENT_LC_CTYPE | — | DB2 | — | — | — | — | — | — |
| CURRENT_PATH | SQL-2016 | DB2 | Mimer | — | — | — | — | Teradata |
| CURRENT_ROLE | SQL-2016 | — | — | — | — | PostgreSQL | — | Teradata |
| CURRENT_ROW | SQL-2016 | — | — | — | — | — | — | — |
| CURRENT_SCHEMA | SQL-2016 | DB2 | — | — | — | PostgreSQL | — | — |
| CURRENT_SERVER | — | DB2 | — | — | — | — | — | — |
| CURRENT_TIME | SQL-2016 | DB2 | Mimer | MySQL | — | PostgreSQL | SQL Server | Teradata |
| CURRENT_TIMESTAMP | SQL-2016 | DB2 | Mimer | MySQL | — | PostgreSQL | SQL Server | Teradata |
| CURRENT_TIMEZONE | — | DB2 | — | — | — | — | — | — |
| CURRENT_USER | SQL-2016 | — | Mimer | MySQL | — | PostgreSQL | SQL Server | Teradata |
| CURRVAL | — | DB2 | — | — | — | — | — | — |
| CURSOR | SQL-2016 | DB2 | Mimer | MySQL | — | — | SQL Server | Teradata |
| CV | — | — | — | — | — | — | — | Teradata |
| CYCLE | SQL-2016 | — | — | — | — | — | — | Teradata |
| DATA | — | DB2 | — | — | — | — | — | Teradata |
| DATABASE | — | DB2 | — | MySQL | — | — | SQL Server | Teradata |
| DATABASES | — | — | — | MySQL | — | — | — | — |
| DATABLOCKSIZE | — | — | — | — | — | — | — | Teradata |
| DATE | SQL-2016 | — | — | — | Oracle | — | — | Teradata |
| DATEFORM | — | — | — | — | — | — | — | Teradata |
| DAY | SQL-2016 | DB2 | Mimer | — | — | — | — | Teradata |
| DAYS | — | DB2 | — | — | — | — | — | — |
| DAY_HOUR | — | — | — | MySQL | — | — | — | — |
| DAY_MICROSECOND | — | — | — | MySQL | — | — | — | — |
| DAY_MINUTE | — | — | — | MySQL | — | — | — | — |
| DAY_SECOND | — | — | — | MySQL | — | — | — | — |
| DBCC | — | — | — | — | — | — | SQL Server | — |
| DBINFO | — | DB2 | — | — | — | — | — | — |
| DEALLOCATE | SQL-2016 | — | Mimer | — | — | — | SQL Server | Teradata |
| DEC | SQL-2016 | — | — | MySQL | — | — | — | Teradata |
| DECFLOAT | SQL-2016 | — | — | — | — | — | — | — |
| DECIMAL | SQL-2016 | — | — | MySQL | Oracle | — | — | Teradata |
| DECLARE | SQL-2016 | DB2 | Mimer | MySQL | — | — | SQL Server | Teradata |
| DEFAULT | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| DEFERRABLE | — | — | — | — | — | PostgreSQL | — | Teradata |
| DEFERRED | — | — | — | — | — | — | — | Teradata |
| DEFINE | SQL-2016 | — | — | — | — | — | — | — |
| DEGREES | — | — | — | — | — | — | — | Teradata |
| DEL | — | — | — | — | — | — | — | Teradata |
| DELAYED | — | — | — | MySQL | — | — | — | — |
| DELETE | SQL-2016 | DB2 | Mimer | MySQL | Oracle | — | SQL Server | Teradata |
| DENSE_RANK | SQL-2016 | — | — | MySQL | — | — | — | — |
| DENY | — | — | — | — | — | — | SQL Server | — |
| DEPTH | — | — | — | — | — | — | — | Teradata |
| DEREF | SQL-2016 | — | — | — | — | — | — | Teradata |
| DESC | — | — | — | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| DESCRIBE | SQL-2016 | — | Mimer | MySQL | — | — | — | Teradata |
| DESCRIPTOR | — | DB2 | — | — | — | — | — | Teradata |
| DESTROY | — | — | — | — | — | — | — | Teradata |
| DESTRUCTOR | — | — | — | — | — | — | — | Teradata |
| DETERMINISTIC | SQL-2016 | DB2 | Mimer | MySQL | — | — | — | Teradata |
| DIAGNOSTIC | — | — | — | — | — | — | — | Teradata |
| DIAGNOSTICS | — | — | — | — | — | — | — | Teradata |
| DICTIONARY | — | — | — | — | — | — | — | Teradata |
| DISABLE | — | DB2 | — | — | — | — | — | — |
| DISABLED | — | — | — | — | — | — | — | Teradata |
| DISALLOW | — | DB2 | — | — | — | — | — | — |
| DISCONNECT | SQL-2016 | — | Mimer | — | — | — | — | Teradata |
| DISK | — | — | — | — | — | — | SQL Server | — |
| DISTINCT | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| DISTINCTROW | — | — | — | MySQL | — | — | — | — |
| DISTRIBUTED | — | — | — | — | — | — | SQL Server | — |
| DIV | — | — | — | MySQL | — | — | — | — |
| DO | SQL/PSM-2016 | DB2 | Mimer | — | — | PostgreSQL | — | Teradata |
| DOCUMENT | — | DB2 | — | — | — | — | — | — |
| DOMAIN | — | — | — | — | — | — | — | Teradata |
| DOUBLE | SQL-2016 | DB2 | — | MySQL | — | — | SQL Server | Teradata |
| DROP | SQL-2016 | DB2 | Mimer | MySQL | Oracle | — | SQL Server | Teradata |
| DSSIZE | — | DB2 | — | — | — | — | — | — |
| DUAL | — | — | — | MySQL | — | — | — | Teradata |
| DUMP | — | — | — | — | — | — | SQL Server | Teradata |
| DYNAMIC | SQL-2016 | DB2 | — | — | — | — | — | Teradata |
| EACH | SQL-2016 | — | — | MySQL | — | — | — | Teradata |
| ECHO | — | — | — | — | — | — | — | Teradata |
| EDITPROC | — | DB2 | — | — | — | — | — | — |
| ELEMENT | SQL-2016 | — | — | — | — | — | — | — |
| ELSE | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| ELSEIF | SQL/PSM-2016 | DB2 | Mimer | MySQL | — | — | — | Teradata |
| EMPTY | SQL-2016 | — | — | MySQL | — | — | — | — |
| ENABLED | — | — | — | — | — | — | — | Teradata |
| ENCLOSED | — | — | — | MySQL | — | — | — | — |
| ENCODING | — | DB2 | — | — | — | — | — | — |
| ENCRYPTION | — | DB2 | — | — | — | — | — | — |
| END | SQL-2016 | DB2 | Mimer | — | — | PostgreSQL | SQL Server | Teradata |
| END-EXEC | SQL-2016 | DB2 | — | — | — | — | — | Teradata |
| ENDING | — | DB2 | — | — | — | — | — | — |
| END_FRAME | SQL-2016 | — | — | — | — | — | — | — |
| END_PARTITION | SQL-2016 | — | — | — | — | — | — | — |
| EQ | — | — | — | — | — | — | — | Teradata |
| EQUALS | SQL-2016 | — | — | — | — | — | — | Teradata |
| ERASE | — | DB2 | — | — | — | — | — | — |
| ERRLVL | — | — | — | — | — | — | SQL Server | — |
| ERROR | — | — | — | — | — | — | — | Teradata |
| ERRORFILES | — | — | — | — | — | — | — | Teradata |
| ERRORTABLES | — | — | — | — | — | — | — | Teradata |
| ESCAPE | SQL-2016 | DB2 | Mimer | — | — | — | SQL Server | Teradata |
| ESCAPED | — | — | — | MySQL | — | — | — | — |
| ET | — | — | — | — | — | — | — | Teradata |
| EVERY | SQL-2016 | — | — | — | — | — | — | Teradata |
| EXCEPT | SQL-2016 | DB2 | Mimer | MySQL | — | PostgreSQL | SQL Server | Teradata |
| EXCEPTION | — | DB2 | — | — | — | — | — | Teradata |
| EXCLUSIVE | — | — | — | — | Oracle | — | — | — |
| EXEC | SQL-2016 | — | — | — | — | — | SQL Server | Teradata |
| EXECUTE | SQL-2016 | DB2 | Mimer | — | — | — | SQL Server | Teradata |
| EXISTS | SQL-2016 | DB2 | Mimer | MySQL | Oracle | — | SQL Server | Teradata |
| EXIT | — | DB2 | — | MySQL | — | — | SQL Server | Teradata |
| EXP | SQL-2016 | — | — | — | — | — | — | Teradata |
| EXPLAIN | — | DB2 | — | MySQL | — | — | — | Teradata |
| EXTERNAL | SQL-2016 | DB2 | Mimer | — | — | — | SQL Server | Teradata |
| EXTRACT | SQL-2016 | — | — | — | — | — | — | Teradata |
| FALLBACK | — | — | — | — | — | — | — | Teradata |
| FALSE | SQL-2016 | — | Mimer | MySQL | — | PostgreSQL | — | Teradata |
| FASTEXPORT | — | — | — | — | — | — | — | Teradata |
| FENCED | — | DB2 | — | — | — | — | — | — |
| FETCH | SQL-2016 | DB2 | Mimer | MySQL | — | PostgreSQL | SQL Server | Teradata |
| FIELDPROC | — | DB2 | — | — | — | — | — | — |
| FILE | — | — | — | — | Oracle | — | SQL Server | — |
| FILLFACTOR | — | — | — | — | — | — | SQL Server | — |
| FILTER | SQL-2016 | — | — | — | — | — | — | — |
| FINAL | — | DB2 | — | — | — | — | — | — |
| FIRST | — | DB2 | Mimer | — | — | — | — | Teradata |
| FIRST_VALUE | SQL-2016 | — | — | MySQL | — | — | — | — |
| FLOAT | SQL-2016 | — | — | MySQL | Oracle | — | — | Teradata |
| FLOAT4 | — | — | — | MySQL | — | — | — | — |
| FLOAT8 | — | — | — | MySQL | — | — | — | — |
| FLOOR | SQL-2016 | — | — | — | — | — | — | — |
| FOR | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| FORCE | — | — | — | MySQL | — | — | — | — |
| FOREIGN | SQL-2016 | — | Mimer | MySQL | — | PostgreSQL | SQL Server | Teradata |
| FORMAT | — | — | — | — | — | — | — | Teradata |
| FOUND | — | — | — | — | — | — | — | Teradata |
| FRAME_ROW | SQL-2016 | — | — | — | — | — | — | — |
| FREE | SQL-2016 | DB2 | — | — | — | — | — | Teradata |
| FREESPACE | — | — | — | — | — | — | — | Teradata |
| FREETEXT | — | — | — | — | — | — | SQL Server | — |
| FREETEXTTABLE | — | — | — | — | — | — | SQL Server | — |
| FREEZE | — | — | — | — | — | PostgreSQL | — | — |
| FROM | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| FULL | SQL-2016 | DB2 | Mimer | — | — | PostgreSQL | SQL Server | Teradata |
| FULLTEXT | — | — | — | MySQL | — | — | — | — |
| FUNCTION | SQL-2016 | DB2 | Mimer | MySQL | — | — | SQL Server | Teradata |
| FUSION | SQL-2016 | — | — | — | — | — | — | — |
| GE | — | — | — | — | — | — | — | Teradata |
| GENERAL | — | — | — | — | — | — | — | Teradata |
| GENERATED | — | DB2 | — | MySQL | — | — | — | Teradata |
| GET | SQL-2016 | DB2 | Mimer | MySQL | — | — | — | Teradata |
| GIVE | — | — | — | — | — | — | — | Teradata |
| GLOBAL | SQL-2016 | DB2 | Mimer | — | — | — | — | Teradata |
| GO | — | DB2 | — | — | — | — | — | Teradata |
| GOTO | — | DB2 | — | — | — | — | SQL Server | Teradata |
| GRANT | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| GRAPHIC | — | — | — | — | — | — | — | Teradata |
| GROUP | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| GROUPING | SQL-2016 | — | — | MySQL | — | — | — | Teradata |
| GROUPS | SQL-2016 | — | — | MySQL | — | — | — | — |
| GT | — | — | — | — | — | — | — | Teradata |
| HANDLER | SQL/PSM-2016 | DB2 | Mimer | — | — | — | — | Teradata |
| HASH | — | — | — | — | — | — | — | Teradata |
| HASHAMP | — | — | — | — | — | — | — | Teradata |
| HASHBAKAMP | — | — | — | — | — | — | — | Teradata |
| HASHBUCKET | — | — | — | — | — | — | — | Teradata |
| HASHROW | — | — | — | — | — | — | — | Teradata |
| HAVING | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| HELP | — | — | — | — | — | — | — | Teradata |
| HIGH_PRIORITY | — | — | — | MySQL | — | — | — | — |
| HOLD | SQL-2016 | DB2 | Mimer | — | — | — | — | — |
| HOLDLOCK | — | — | — | — | — | — | SQL Server | — |
| HOST | — | — | — | — | — | — | — | Teradata |
| HOUR | SQL-2016 | DB2 | Mimer | — | — | — | — | Teradata |
| HOURS | — | DB2 | — | — | — | — | — | — |
| HOUR_MICROSECOND | — | — | — | MySQL | — | — | — | — |
| HOUR_MINUTE | — | — | — | MySQL | — | — | — | — |
| HOUR_SECOND | — | — | — | MySQL | — | — | — | — |
| IDENTIFIED | — | — | — | — | Oracle | — | — | — |
| IDENTITY | SQL-2016 | — | Mimer | — | — | — | SQL Server | Teradata |
| IDENTITYCOL | — | — | — | — | — | — | SQL Server | — |
| IDENTITY_INSERT | — | — | — | — | — | — | SQL Server | — |
| IF | SQL/PSM-2016 | DB2 | Mimer | MySQL | — | — | SQL Server | Teradata |
| IGNORE | — | — | — | MySQL | — | — | — | Teradata |
| ILIKE | — | — | — | — | — | PostgreSQL | — | — |
| IMMEDIATE | — | DB2 | — | — | Oracle | — | — | Teradata |
| IN | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| INCLUSIVE | — | DB2 | — | — | — | — | — | — |
| INCONSISTENT | — | — | — | — | — | — | — | Teradata |
| INCREMENT | — | — | — | — | Oracle | — | — | — |
| INDEX | — | DB2 | — | MySQL | Oracle | — | SQL Server | Teradata |
| INDICATOR | SQL-2016 | — | Mimer | — | — | — | — | Teradata |
| INFILE | — | — | — | MySQL | — | — | — | — |
| INHERIT | — | DB2 | — | — | — | — | — | — |
| INITIAL | SQL-2016 | — | — | — | Oracle | — | — | — |
| INITIALIZE | — | — | — | — | — | — | — | Teradata |
| INITIALLY | — | — | — | — | — | PostgreSQL | — | Teradata |
| INITIATE | — | — | — | — | — | — | — | Teradata |
| INNER | SQL-2016 | DB2 | Mimer | MySQL | — | PostgreSQL | SQL Server | Teradata |
| INOUT | SQL-2016 | DB2 | Mimer | MySQL | — | — | — | Teradata |
| INPUT | — | — | — | — | — | — | — | Teradata |
| INS | — | — | — | — | — | — | — | Teradata |
| INSENSITIVE | SQL-2016 | DB2 | — | MySQL | — | — | — | — |
| INSERT | SQL-2016 | DB2 | Mimer | MySQL | Oracle | — | SQL Server | Teradata |
| INSTEAD | — | — | — | — | — | — | — | Teradata |
| INT | SQL-2016 | — | — | MySQL | — | — | — | Teradata |
| INT1 | — | — | — | MySQL | — | — | — | — |
| INT2 | — | — | — | MySQL | — | — | — | — |
| INT3 | — | — | — | MySQL | — | — | — | — |
| INT4 | — | — | — | MySQL | — | — | — | — |
| INT8 | — | — | — | MySQL | — | — | — | — |
| INTEGER | SQL-2016 | — | — | MySQL | Oracle | — | — | Teradata |
| INTEGERDATE | — | — | — | — | — | — | — | Teradata |
| INTERSECT | SQL-2016 | DB2 | Mimer | — | Oracle | PostgreSQL | SQL Server | Teradata |
| INTERSECTION | SQL-2016 | — | — | — | — | — | — | — |
| INTERVAL | SQL-2016 | — | Mimer | MySQL | — | — | — | Teradata |
| INTO | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| IO_AFTER_GTIDS | — | — | — | MySQL | — | — | — | — |
| IO_BEFORE_GTIDS | — | — | — | MySQL | — | — | — | — |
| IS | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| ISNULL | — | — | — | — | — | PostgreSQL | — | — |
| ISOBID | — | DB2 | — | — | — | — | — | — |
| ISOLATION | — | — | — | — | — | — | — | Teradata |
| ITERATE | SQL/PSM-2016 | DB2 | Mimer | MySQL | — | — | — | Teradata |
| JAR | — | DB2 | — | — | — | — | — | — |
| JOIN | SQL-2016 | DB2 | Mimer | MySQL | — | PostgreSQL | SQL Server | Teradata |
| JOURNAL | — | — | — | — | — | — | — | Teradata |
| JSON | SQL-2016 | — | — | — | — | — | — | — |
| JSON_ARRAY | SQL-2016 | — | — | — | — | — | — | — |
| JSON_ARRAYAGG | SQL-2016 | — | — | — | — | — | — | — |
| JSON_EXISTS | SQL-2016 | — | — | — | — | — | — | — |
| JSON_OBJECT | SQL-2016 | — | — | — | — | — | — | — |
| JSON_OBJECTAGG | SQL-2016 | — | — | — | — | — | — | — |
| JSON_QUERY | SQL-2016 | — | — | — | — | — | — | — |
| JSON_TABLE | SQL-2016 | — | — | MySQL | — | — | — | — |
| JSON_TABLE_PRIMITIVE | SQL-2016 | — | — | — | — | — | — | — |
| JSON_VALUE | SQL-2016 | — | — | — | — | — | — | — |
| KEEP | — | DB2 | — | — | — | — | — | — |
| KEY | — | DB2 | — | MySQL | — | — | SQL Server | Teradata |
| KEYS | — | — | — | MySQL | — | — | — | — |
| KILL | — | — | — | MySQL | — | — | SQL Server | — |
| KURTOSIS | — | — | — | — | — | — | — | Teradata |
| LABEL | — | DB2 | — | — | — | — | — | — |
| LAG | SQL-2016 | — | — | MySQL | — | — | — | — |
| LANGUAGE | SQL-2016 | DB2 | Mimer | — | — | — | — | Teradata |
| LARGE | SQL-2016 | — | Mimer | — | — | — | — | Teradata |
| LAST | — | DB2 | — | — | — | — | — | Teradata |
| LAST_VALUE | SQL-2016 | — | — | MySQL | — | — | — | — |
| LATERAL | SQL-2016 | — | — | MySQL | — | PostgreSQL | — | Teradata |
| LC_CTYPE | — | DB2 | — | — | — | — | — | — |
| LE | — | — | — | — | — | — | — | Teradata |
| LEAD | SQL-2016 | — | — | MySQL | — | — | — | — |
| LEADING | SQL-2016 | — | Mimer | MySQL | — | PostgreSQL | — | Teradata |
| LEAVE | SQL/PSM-2016 | DB2 | Mimer | MySQL | — | — | — | Teradata |
| LEFT | SQL-2016 | DB2 | Mimer | MySQL | — | PostgreSQL | SQL Server | Teradata |
| LESS | — | — | — | — | — | — | — | Teradata |
| LEVEL | — | — | — | — | Oracle | — | — | Teradata |
| LIKE | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| LIKE_REGEX | SQL-2016 | — | — | — | — | — | — | — |
| LIMIT | — | DB2 | — | MySQL | — | PostgreSQL | — | Teradata |
| LINEAR | — | — | — | MySQL | — | — | — | — |
| LINENO | — | — | — | — | — | — | SQL Server | — |
| LINES | — | — | — | MySQL | — | — | — | — |
| LISTAGG | SQL-2016 | — | — | — | — | — | — | — |
| LN | SQL-2016 | — | — | — | — | — | — | Teradata |
| LOAD | — | — | — | MySQL | — | — | SQL Server | — |
| LOADING | — | — | — | — | — | — | — | Teradata |
| LOCAL | SQL-2016 | DB2 | Mimer | — | — | — | — | Teradata |
| LOCALE | — | DB2 | — | — | — | — | — | — |
| LOCALTIME | SQL-2016 | — | Mimer | MySQL | — | PostgreSQL | — | Teradata |
| LOCALTIMESTAMP | SQL-2016 | — | Mimer | MySQL | — | PostgreSQL | — | Teradata |
| LOCATOR | — | DB2 | — | — | — | — | — | Teradata |
| LOCATORS | — | DB2 | — | — | — | — | — | — |
| LOCK | — | DB2 | — | MySQL | Oracle | — | — | Teradata |
| LOCKING | — | — | — | — | — | — | — | Teradata |
| LOCKMAX | — | DB2 | — | — | — | — | — | — |
| LOCKSIZE | — | DB2 | — | — | — | — | — | — |
| LOG | SQL-2016 | — | — | — | — | — | — | Teradata |
| LOG10 | SQL-2016 | — | — | — | — | — | — | — |
| LOGGING | — | — | — | — | — | — | — | Teradata |
| LOGON | — | — | — | — | — | — | — | Teradata |
| LONG | — | DB2 | — | MySQL | Oracle | — | — | Teradata |
| LONGBLOB | — | — | — | MySQL | — | — | — | — |
| LONGTEXT | — | — | — | MySQL | — | — | — | — |
| LOOP | SQL/PSM-2016 | DB2 | Mimer | MySQL | — | — | — | Teradata |
| LOWER | SQL-2016 | — | — | — | — | — | — | Teradata |
| LOW_PRIORITY | — | — | — | MySQL | — | — | — | — |
| LT | — | — | — | — | — | — | — | Teradata |
| MACRO | — | — | — | — | — | — | — | Teradata |
| MAINTAINED | — | DB2 | — | — | — | — | — | — |
| MAP | — | — | — | — | — | — | — | Teradata |
| MASTER_BIND | — | — | — | MySQL | — | — | — | — |
| MATCH | SQL-2016 | — | Mimer | MySQL | — | — | — | Teradata |
| MATCHES | SQL-2016 | — | — | — | — | — | — | — |
| MATCH_NUMBER | SQL-2016 | — | — | — | — | — | — | — |
| MATCH_RECOGNIZE | SQL-2016 | — | — | — | — | — | — | — |
| MATERIALIZED | — | DB2 | — | — | — | — | — | — |
| MAVG | — | — | — | — | — | — | — | Teradata |
| MAX | SQL-2016 | — | — | — | — | — | — | Teradata |
| MAXEXTENTS | — | — | — | — | Oracle | — | — | — |
| MAXIMUM | — | — | — | — | — | — | — | Teradata |
| MAXVALUE | — | — | — | MySQL | — | — | — | — |
| MCHARACTERS | — | — | — | — | — | — | — | Teradata |
| MDIFF | — | — | — | — | — | — | — | Teradata |
| MEDIUMBLOB | — | — | — | MySQL | — | — | — | — |
| MEDIUMINT | — | — | — | MySQL | — | — | — | — |
| MEDIUMTEXT | — | — | — | MySQL | — | — | — | — |
| MEMBER | SQL-2016 | — | Mimer | — | — | — | — | — |
| MERGE | SQL-2016 | — | — | — | — | — | SQL Server | Teradata |
| METHOD | SQL-2016 | — | Mimer | — | — | — | — | — |
| MICROSECOND | — | DB2 | — | — | — | — | — | — |
| MICROSECONDS | — | DB2 | — | — | — | — | — | — |
| MIDDLEINT | — | — | — | MySQL | — | — | — | — |
| MIN | SQL-2016 | — | — | — | — | — | — | Teradata |
| MINDEX | — | — | — | — | — | — | — | Teradata |
| MINIMUM | — | — | — | — | — | — | — | Teradata |
| MINUS | — | — | — | — | Oracle | — | — | Teradata |
| MINUTE | SQL-2016 | DB2 | Mimer | — | — | — | — | Teradata |
| MINUTES | — | DB2 | — | — | — | — | — | — |
| MINUTE_MICROSECOND | — | — | — | MySQL | — | — | — | — |
| MINUTE_SECOND | — | — | — | MySQL | — | — | — | — |
| MLINREG | — | — | — | — | — | — | — | Teradata |
| MLOAD | — | — | — | — | — | — | — | Teradata |
| MLSLABEL | — | — | — | — | Oracle | — | — | — |
| MOD | SQL-2016 | — | — | MySQL | — | — | — | Teradata |
| MODE | — | — | — | — | Oracle | — | — | Teradata |
| MODIFIES | SQL-2016 | DB2 | Mimer | MySQL | — | — | — | Teradata |
| MODIFY | — | — | — | — | Oracle | — | — | Teradata |
| MODULE | SQL-2016 | — | Mimer | — | — | — | — | Teradata |
| MONITOR | — | — | — | — | — | — | — | Teradata |
| MONRESOURCE | — | — | — | — | — | — | — | Teradata |
| MONSESSION | — | — | — | — | — | — | — | Teradata |
| MONTH | SQL-2016 | DB2 | Mimer | — | — | — | — | Teradata |
| MONTHS | — | DB2 | — | — | — | — | — | — |
| MSUBSTR | — | — | — | — | — | — | — | Teradata |
| MSUM | — | — | — | — | — | — | — | Teradata |
| MULTISET | SQL-2016 | — | — | — | — | — | — | Teradata |
| NAMED | — | — | — | — | — | — | — | Teradata |
| NAMES | — | — | — | — | — | — | — | Teradata |
| NATIONAL | SQL-2016 | — | Mimer | — | — | — | SQL Server | Teradata |
| NATURAL | SQL-2016 | — | Mimer | MySQL | — | PostgreSQL | — | Teradata |
| NCHAR | SQL-2016 | — | — | — | — | — | — | Teradata |
| NCLOB | SQL-2016 | — | — | — | — | — | — | Teradata |
| NE | — | — | — | — | — | — | — | Teradata |
| NESTED_TABLE_ID | — | — | — | — | Oracle | — | — | — |
| NEW | SQL-2016 | — | Mimer | — | — | — | — | Teradata |
| NEW_TABLE | — | — | — | — | — | — | — | Teradata |
| NEXT | — | DB2 | Mimer | — | — | — | — | Teradata |
| NEXTVAL | — | DB2 | — | — | — | — | — | — |
| NO | SQL-2016 | DB2 | Mimer | — | — | — | — | Teradata |
| NOAUDIT | — | — | — | — | Oracle | — | — | — |
| NOCHECK | — | — | — | — | — | — | SQL Server | — |
| NOCOMPRESS | — | — | — | — | Oracle | — | — | — |
| NONCLUSTERED | — | — | — | — | — | — | SQL Server | — |
| NONE | SQL-2016 | DB2 | — | — | — | — | — | Teradata |
| NORMALIZE | SQL-2016 | — | — | — | — | — | — | — |
| NOT | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| NOTNULL | — | — | — | — | — | PostgreSQL | — | — |
| NOWAIT | — | — | — | — | Oracle | — | — | Teradata |
| NO_WRITE_TO_BINLOG | — | — | — | MySQL | — | — | — | — |
| NTH_VALUE | SQL-2016 | — | — | MySQL | — | — | — | — |
| NTILE | SQL-2016 | — | — | MySQL | — | — | — | — |
| NULL | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| NULLIF | SQL-2016 | — | — | — | — | — | SQL Server | Teradata |
| NULLIFZERO | — | — | — | — | — | — | — | Teradata |
| NULLS | — | DB2 | — | — | — | — | — | — |
| NUMBER | — | — | — | — | Oracle | — | — | — |
| NUMERIC | SQL-2016 | — | — | MySQL | — | — | — | Teradata |
| NUMPARTS | — | DB2 | — | — | — | — | — | — |
| OBID | — | DB2 | — | — | — | — | — | — |
| OBJECT | — | — | — | — | — | — | — | Teradata |
| OBJECTS | — | — | — | — | — | — | — | Teradata |
| OCCURRENCES_REGEX | SQL-2016 | — | — | — | — | — | — | — |
| OCTET_LENGTH | SQL-2016 | — | — | — | — | — | — | Teradata |
| OF | SQL-2016 | DB2 | Mimer | MySQL | Oracle | — | SQL Server | Teradata |
| OFF | — | — | — | — | — | — | SQL Server | Teradata |
| OFFLINE | — | — | — | — | Oracle | — | — | — |
| OFFSET | SQL-2016 | DB2 | Mimer | — | — | PostgreSQL | — | — |
| OFFSETS | — | — | — | — | — | — | SQL Server | — |
| OLD | SQL-2016 | DB2 | Mimer | — | — | — | — | Teradata |
| OLD_TABLE | — | — | — | — | — | — | — | Teradata |
| OMIT | SQL-2016 | — | — | — | — | — | — | — |
| ON | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| ONE | SQL-2016 | — | — | — | — | — | — | — |
| ONLINE | — | — | — | — | Oracle | — | — | — |
| ONLY | SQL-2016 | — | — | — | — | PostgreSQL | — | Teradata |
| OPEN | SQL-2016 | DB2 | Mimer | — | — | — | SQL Server | Teradata |
| OPENDATASOURCE | — | — | — | — | — | — | SQL Server | — |
| OPENQUERY | — | — | — | — | — | — | SQL Server | — |
| OPENROWSET | — | — | — | — | — | — | SQL Server | — |
| OPENXML | — | — | — | — | — | — | SQL Server | — |
| OPERATION | — | — | — | — | — | — | — | Teradata |
| OPTIMIZATION | — | DB2 | — | — | — | — | — | — |
| OPTIMIZE | — | DB2 | — | MySQL | — | — | — | — |
| OPTIMIZER_COSTS | — | — | — | MySQL | — | — | — | — |
| OPTION | — | — | — | MySQL | Oracle | — | SQL Server | Teradata |
| OPTIONALLY | — | — | — | MySQL | — | — | — | — |
| OR | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| ORDER | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| ORDINALITY | — | — | — | — | — | — | — | Teradata |
| ORGANIZATION | — | DB2 | — | — | — | — | — | — |
| OUT | SQL-2016 | DB2 | Mimer | MySQL | — | — | — | Teradata |
| OUTER | SQL-2016 | DB2 | — | MySQL | — | PostgreSQL | SQL Server | Teradata |
| OUTFILE | — | — | — | MySQL | — | — | — | — |
| OUTPUT | — | — | — | — | — | — | — | Teradata |
| OVER | SQL-2016 | — | — | MySQL | — | — | SQL Server | Teradata |
| OVERLAPS | SQL-2016 | — | Mimer | — | — | PostgreSQL | — | Teradata |
| OVERLAY | SQL-2016 | — | — | — | — | — | — | — |
| OVERRIDE | — | — | — | — | — | — | — | Teradata |
| PACKAGE | — | DB2 | — | — | — | — | — | — |
| PAD | — | — | — | — | — | — | — | Teradata |
| PADDED | — | DB2 | — | — | — | — | — | — |
| PARAMETER | SQL-2016 | DB2 | Mimer | — | — | — | — | Teradata |
| PARAMETERS | — | — | — | — | — | — | — | Teradata |
| PART | — | DB2 | — | — | — | — | — | — |
| PARTIAL | — | — | — | — | — | — | — | Teradata |
| PARTITION | SQL-2016 | DB2 | — | MySQL | — | — | — | — |
| PARTITIONED | — | DB2 | — | — | — | — | — | — |
| PARTITIONING | — | DB2 | — | — | — | — | — | — |
| PASSWORD | — | — | — | — | — | — | — | Teradata |
| PATH | — | DB2 | — | — | — | — | — | Teradata |
| PATTERN | SQL-2016 | — | — | — | — | — | — | — |
| PCTFREE | — | — | — | — | Oracle | — | — | — |
| PER | SQL-2016 | — | — | — | — | — | — | — |
| PERCENT | SQL-2016 | — | — | — | — | — | SQL Server | Teradata |
| PERCENTILE_CONT | SQL-2016 | — | — | — | — | — | — | — |
| PERCENTILE_DISC | SQL-2016 | — | — | — | — | — | — | — |
| PERCENT_RANK | SQL-2016 | — | — | MySQL | — | — | — | Teradata |
| PERIOD | SQL-2016 | DB2 | — | — | — | — | — | — |
| PERM | — | — | — | — | — | — | — | Teradata |
| PERMANENT | — | — | — | — | — | — | — | Teradata |
| PIECESIZE | — | DB2 | — | — | — | — | — | — |
| PIVOT | — | — | — | — | — | — | SQL Server | — |
| PLACING | — | — | — | — | — | PostgreSQL | — | — |
| PLAN | — | DB2 | — | — | — | — | SQL Server | — |
| PORTION | SQL-2016 | — | — | — | — | — | — | — |
| POSITION | SQL-2016 | — | — | — | — | — | — | Teradata |
| POSITION_REGEX | SQL-2016 | — | — | — | — | — | — | — |
| POSTFIX | — | — | — | — | — | — | — | Teradata |
| POWER | SQL-2016 | — | — | — | — | — | — | — |
| PRECEDES | SQL-2016 | — | — | — | — | — | — | — |
| PRECISION | SQL-2016 | DB2 | Mimer | MySQL | — | — | SQL Server | Teradata |
| PREFIX | — | — | — | — | — | — | — | Teradata |
| PREORDER | — | — | — | — | — | — | — | Teradata |
| PREPARE | SQL-2016 | DB2 | Mimer | — | — | — | — | Teradata |
| PRESERVE | — | — | — | — | — | — | — | Teradata |
| PREVVAL | — | DB2 | — | — | — | — | — | — |
| PRIMARY | SQL-2016 | — | Mimer | MySQL | — | PostgreSQL | SQL Server | Teradata |
| — | — | — | — | — | — | SQL Server | — | |
| PRIOR | — | DB2 | — | — | Oracle | — | — | Teradata |
| PRIQTY | — | DB2 | — | — | — | — | — | — |
| PRIVATE | — | — | — | — | — | — | — | Teradata |
| PRIVILEGES | — | DB2 | — | — | — | — | — | Teradata |
| PROC | — | — | — | — | — | — | SQL Server | — |
| PROCEDURE | SQL-2016 | DB2 | Mimer | MySQL | — | — | SQL Server | Teradata |
| PROFILE | — | — | — | — | — | — | — | Teradata |
| PROGRAM | — | DB2 | — | — | — | — | — | — |
| PROPORTIONAL | — | — | — | — | — | — | — | Teradata |
| PROTECTION | — | — | — | — | — | — | — | Teradata |
| PSID | — | DB2 | — | — | — | — | — | — |
| PTF | SQL-2016 | — | — | — | — | — | — | — |
| PUBLIC | — | DB2 | — | — | Oracle | — | SQL Server | Teradata |
| PURGE | — | — | — | MySQL | — | — | — | — |
| QUALIFIED | — | — | — | — | — | — | — | Teradata |
| QUALIFY | — | — | — | — | — | — | — | Teradata |
| QUANTILE | — | — | — | — | — | — | — | Teradata |
| QUERY | — | DB2 | — | — | — | — | — | — |
| QUERYNO | — | DB2 | — | — | — | — | — | — |
| RADIANS | — | — | — | — | — | — | — | Teradata |
| RAISERROR | — | — | — | — | — | — | SQL Server | — |
| RANDOM | — | — | — | — | — | — | — | Teradata |
| RANGE | SQL-2016 | — | — | MySQL | — | — | — | — |
| RANGE_N | — | — | — | — | — | — | — | Teradata |
| RANK | SQL-2016 | — | — | MySQL | — | — | — | Teradata |
| RAW | — | — | — | — | Oracle | — | — | — |
| READ | — | — | — | MySQL | — | — | SQL Server | Teradata |
| READS | SQL-2016 | DB2 | Mimer | MySQL | — | — | — | Teradata |
| READTEXT | — | — | — | — | — | — | SQL Server | — |
| READ_WRITE | — | — | — | MySQL | — | — | — | — |
| REAL | SQL-2016 | — | — | MySQL | — | — | — | Teradata |
| RECONFIGURE | — | — | — | — | — | — | SQL Server | — |
| RECURSIVE | SQL-2016 | — | Mimer | MySQL | — | — | — | Teradata |
| REF | SQL-2016 | — | — | — | — | — | — | Teradata |
| REFERENCES | SQL-2016 | DB2 | Mimer | MySQL | — | PostgreSQL | SQL Server | Teradata |
| REFERENCING | SQL-2016 | — | Mimer | — | — | — | — | Teradata |
| REFRESH | — | DB2 | — | — | — | — | — | — |
| REGEXP | — | — | — | MySQL | — | — | — | — |
| REGR_AVGX | SQL-2016 | — | — | — | — | — | — | Teradata |
| REGR_AVGY | SQL-2016 | — | — | — | — | — | — | Teradata |
| REGR_COUNT | SQL-2016 | — | — | — | — | — | — | Teradata |
| REGR_INTERCEPT | SQL-2016 | — | — | — | — | — | — | Teradata |
| REGR_R2 | SQL-2016 | — | — | — | — | — | — | Teradata |
| REGR_SLOPE | SQL-2016 | — | — | — | — | — | — | Teradata |
| REGR_SXX | SQL-2016 | — | — | — | — | — | — | Teradata |
| REGR_SXY | SQL-2016 | — | — | — | — | — | — | Teradata |
| REGR_SYY | SQL-2016 | — | — | — | — | — | — | Teradata |
| RELATIVE | — | — | — | — | — | — | — | Teradata |
| RELEASE | SQL-2016 | DB2 | Mimer | MySQL | — | — | — | Teradata |
| RENAME | — | DB2 | — | MySQL | Oracle | — | — | Teradata |
| REPEAT | SQL/PSM-2016 | DB2 | Mimer | MySQL | — | — | — | Teradata |
| REPLACE | — | — | — | MySQL | — | — | — | Teradata |
| REPLICATION | — | — | — | — | — | — | SQL Server | Teradata |
| REPOVERRIDE | — | — | — | — | — | — | — | Teradata |
| REQUEST | — | — | — | — | — | — | — | Teradata |
| REQUIRE | — | — | — | MySQL | — | — | — | — |
| RESIGNAL | SQL/PSM-2016 | DB2 | Mimer | MySQL | — | — | — | — |
| RESOURCE | — | — | — | — | Oracle | — | — | — |
| RESTART | — | — | — | — | — | — | — | Teradata |
| RESTORE | — | — | — | — | — | — | SQL Server | Teradata |
| RESTRICT | — | DB2 | — | MySQL | — | — | SQL Server | Teradata |
| RESULT | SQL-2016 | DB2 | Mimer | — | — | — | — | Teradata |
| RESULT_SET_LOCATOR | — | DB2 | — | — | — | — | — | — |
| RESUME | — | — | — | — | — | — | — | Teradata |
| RET | — | — | — | — | — | — | — | Teradata |
| RETRIEVE | — | — | — | — | — | — | — | Teradata |
| RETURN | SQL-2016 | DB2 | Mimer | MySQL | — | — | SQL Server | Teradata |
| RETURNING | — | — | — | — | — | PostgreSQL | — | — |
| RETURNS | SQL-2016 | DB2 | Mimer | — | — | — | — | Teradata |
| REVALIDATE | — | — | — | — | — | — | — | Teradata |
| REVERT | — | — | — | — | — | — | SQL Server | — |
| REVOKE | SQL-2016 | DB2 | Mimer | MySQL | Oracle | — | SQL Server | Teradata |
| RIGHT | SQL-2016 | DB2 | Mimer | MySQL | — | PostgreSQL | SQL Server | Teradata |
| RIGHTS | — | — | — | — | — | — | — | Teradata |
| RLIKE | — | — | — | MySQL | — | — | — | — |
| ROLE | — | DB2 | — | — | — | — | — | Teradata |
| ROLLBACK | SQL-2016 | DB2 | Mimer | — | — | — | SQL Server | Teradata |
| ROLLFORWARD | — | — | — | — | — | — | — | Teradata |
| ROLLUP | SQL-2016 | DB2 | — | — | — | — | — | Teradata |
| ROUND_CEILING | — | DB2 | — | — | — | — | — | — |
| ROUND_DOWN | — | DB2 | — | — | — | — | — | — |
| ROUND_FLOOR | — | DB2 | — | — | — | — | — | — |
| ROUND_HALF_DOWN | — | DB2 | — | — | — | — | — | — |
| ROUND_HALF_EVEN | — | DB2 | — | — | — | — | — | — |
| ROUND_HALF_UP | — | DB2 | — | — | — | — | — | — |
| ROUND_UP | — | DB2 | — | — | — | — | — | — |
| ROUTINE | — | — | — | — | — | — | — | Teradata |
| ROW | SQL-2016 | DB2 | Mimer | MySQL | Oracle | — | — | Teradata |
| ROWCOUNT | — | — | — | — | — | — | SQL Server | — |
| ROWGUIDCOL | — | — | — | — | — | — | SQL Server | — |
| ROWID | — | — | — | — | Oracle | — | — | Teradata |
| ROWNUM | — | — | — | — | Oracle | — | — | — |
| ROWS | SQL-2016 | — | Mimer | MySQL | Oracle | — | — | Teradata |
| ROWSET | — | DB2 | — | — | — | — | — | — |
| ROW_NUMBER | SQL-2016 | — | — | MySQL | — | — | — | Teradata |
| RULE | — | — | — | — | — | — | SQL Server | — |
| RUN | — | DB2 | — | — | — | — | — | — |
| RUNNING | SQL-2016 | — | — | — | — | — | — | — |
| SAMPLE | — | — | — | — | — | — | — | Teradata |
| SAMPLEID | — | — | — | — | — | — | — | Teradata |
| SAVE | — | — | — | — | — | — | SQL Server | — |
| SAVEPOINT | SQL-2016 | DB2 | — | — | — | — | — | Teradata |
| SCHEMA | — | DB2 | — | MySQL | — | — | SQL Server | Teradata |
| SCHEMAS | — | — | — | MySQL | — | — | — | — |
| SCOPE | SQL-2016 | — | — | — | — | — | — | Teradata |
| SCRATCHPAD | — | DB2 | — | — | — | — | — | — |
| SCROLL | SQL-2016 | — | Mimer | — | — | — | — | Teradata |
| SEARCH | SQL-2016 | — | — | — | — | — | — | Teradata |
| SECOND | SQL-2016 | DB2 | Mimer | — | — | — | — | Teradata |
| SECONDS | — | DB2 | — | — | — | — | — | — |
| SECOND_MICROSECOND | — | — | — | MySQL | — | — | — | — |
| SECQTY | — | DB2 | — | — | — | — | — | — |
| SECTION | — | — | — | — | — | — | — | Teradata |
| SECURITY | — | DB2 | — | — | — | — | — | — |
| SECURITYAUDIT | — | — | — | — | — | — | SQL Server | — |
| SEEK | SQL-2016 | — | — | — | — | — | — | — |
| SEL | — | — | — | — | — | — | — | Teradata |
| SELECT | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| SEMANTICKEYPHRASETABLE | — | — | — | — | — | — | SQL Server | — |
| SEMANTICSIMILARITYTABLE | — | — | — | — | — | — | SQL Server | — |
| SENSITIVE | SQL-2016 | DB2 | — | MySQL | — | — | — | — |
| SEPARATOR | — | — | — | MySQL | — | — | — | — |
| SEQUENCE | — | DB2 | — | — | — | — | — | Teradata |
| SESSION | — | — | — | — | Oracle | — | — | Teradata |
| SESSION_USER | SQL-2016 | DB2 | Mimer | — | — | PostgreSQL | SQL Server | Teradata |
| SET | SQL-2016 | DB2 | Mimer | MySQL | Oracle | — | SQL Server | Teradata |
| SETRESRATE | — | — | — | — | — | — | — | Teradata |
| SETS | — | — | — | — | — | — | — | Teradata |
| SETSESSRATE | — | — | — | — | — | — | — | Teradata |
| SETUSER | — | — | — | — | — | — | SQL Server | — |
| SHARE | — | — | — | — | Oracle | — | — | — |
| SHOW | SQL-2016 | — | — | MySQL | — | — | — | Teradata |
| SHUTDOWN | — | — | — | — | — | — | SQL Server | — |
| SIGNAL | SQL/PSM-2016 | DB2 | Mimer | MySQL | — | — | — | — |
| SIMILAR | SQL-2016 | — | — | — | — | PostgreSQL | — | — |
| SIMPLE | — | DB2 | — | — | — | — | — | — |
| SIN | SQL-2016 | — | — | — | — | — | — | Teradata |
| SINH | SQL-2016 | — | — | — | — | — | — | Teradata |
| SIZE | — | — | — | — | Oracle | — | — | Teradata |
| SKEW | — | — | — | — | — | — | — | Teradata |
| SKIP | SQL-2016 | — | — | — | — | — | — | — |
| SMALLINT | SQL-2016 | — | — | MySQL | Oracle | — | — | Teradata |
| SOME | SQL-2016 | DB2 | Mimer | — | — | PostgreSQL | SQL Server | Teradata |
| SOUNDEX | — | — | — | — | — | — | — | Teradata |
| SOURCE | — | DB2 | — | — | — | — | — | — |
| SPACE | — | — | — | — | — | — | — | Teradata |
| SPATIAL | — | — | — | MySQL | — | — | — | — |
| SPECIFIC | SQL-2016 | DB2 | Mimer | MySQL | — | — | — | Teradata |
| SPECIFICTYPE | SQL-2016 | — | — | — | — | — | — | Teradata |
| SPOOL | — | — | — | — | — | — | — | Teradata |
| SQL | SQL-2016 | — | Mimer | MySQL | — | — | — | Teradata |
| SQLEXCEPTION | SQL-2016 | — | Mimer | MySQL | — | — | — | Teradata |
| SQLSTATE | SQL-2016 | — | Mimer | MySQL | — | — | — | Teradata |
| SQLTEXT | — | — | — | — | — | — | — | Teradata |
| SQLWARNING | SQL-2016 | — | Mimer | MySQL | — | — | — | Teradata |
| SQL_BIG_RESULT | — | — | — | MySQL | — | — | — | — |
| SQL_CALC_FOUND_ROWS | — | — | — | MySQL | — | — | — | — |
| SQL_SMALL_RESULT | — | — | — | MySQL | — | — | — | — |
| SQRT | SQL-2016 | — | — | — | — | — | — | Teradata |
| SS | — | — | — | — | — | — | — | Teradata |
| SSL | — | — | — | MySQL | — | — | — | — |
| STANDARD | — | DB2 | — | — | — | — | — | — |
| START | SQL-2016 | — | Mimer | — | Oracle | — | — | Teradata |
| STARTING | — | — | — | MySQL | — | — | — | — |
| STARTUP | — | — | — | — | — | — | — | Teradata |
| STATE | — | — | — | — | — | — | — | Teradata |
| STATEMENT | — | DB2 | — | — | — | — | — | Teradata |
| STATIC | SQL-2016 | DB2 | Mimer | — | — | — | — | Teradata |
| STATISTICS | — | — | — | — | — | — | SQL Server | Teradata |
| STAY | — | DB2 | — | — | — | — | — | — |
| STDDEV_POP | SQL-2016 | — | — | — | — | — | — | Teradata |
| STDDEV_SAMP | SQL-2016 | — | — | — | — | — | — | Teradata |
| STEPINFO | — | — | — | — | — | — | — | Teradata |
| STOGROUP | — | DB2 | — | — | — | — | — | — |
| STORED | — | — | — | MySQL | — | — | — | — |
| STORES | — | DB2 | — | — | — | — | — | — |
| STRAIGHT_JOIN | — | — | — | MySQL | — | — | — | — |
| STRING_CS | — | — | — | — | — | — | — | Teradata |
| STRUCTURE | — | — | — | — | — | — | — | Teradata |
| STYLE | — | DB2 | — | — | — | — | — | — |
| SUBMULTISET | SQL-2016 | — | — | — | — | — | — | — |
| SUBSCRIBER | — | — | — | — | — | — | — | Teradata |
| SUBSET | SQL-2016 | — | — | — | — | — | — | — |
| SUBSTR | — | — | — | — | — | — | — | Teradata |
| SUBSTRING | SQL-2016 | — | — | — | — | — | — | Teradata |
| SUBSTRING_REGEX | SQL-2016 | — | — | — | — | — | — | — |
| SUCCEEDS | SQL-2016 | — | — | — | — | — | — | — |
| SUCCESSFUL | — | — | — | — | Oracle | — | — | — |
| SUM | SQL-2016 | — | — | — | — | — | — | Teradata |
| SUMMARY | — | DB2 | — | — | — | — | — | Teradata |
| SUSPEND | — | — | — | — | — | — | — | Teradata |
| SYMMETRIC | SQL-2016 | — | Mimer | — | — | PostgreSQL | — | — |
| SYNONYM | — | DB2 | — | — | Oracle | — | — | — |
| SYSDATE | — | DB2 | — | — | Oracle | — | — | — |
| SYSTEM | SQL-2016 | DB2 | — | MySQL | — | — | — | — |
| SYSTEM_TIME | SQL-2016 | — | — | — | — | — | — | — |
| SYSTEM_USER | SQL-2016 | — | Mimer | — | — | — | SQL Server | Teradata |
| SYSTIMESTAMP | — | DB2 | — | — | — | — | — | — |
| TABLE | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| TABLESAMPLE | SQL-2016 | — | — | — | — | PostgreSQL | SQL Server | — |
| TABLESPACE | — | DB2 | — | — | — | — | — | — |
| TAN | SQL-2016 | — | — | — | — | — | — | Teradata |
| TANH | SQL-2016 | — | — | — | — | — | — | Teradata |
| TBL_CS | — | — | — | — | — | — | — | Teradata |
| TEMPORARY | — | — | — | — | — | — | — | Teradata |
| TERMINATE | — | — | — | — | — | — | — | Teradata |
| TERMINATED | — | — | — | MySQL | — | — | — | — |
| TEXTSIZE | — | — | — | — | — | — | SQL Server | — |
| THAN | — | — | — | — | — | — | — | Teradata |
| THEN | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| THRESHOLD | — | — | — | — | — | — | — | Teradata |
| TIME | SQL-2016 | — | — | — | — | — | — | Teradata |
| TIMESTAMP | SQL-2016 | — | — | — | — | — | — | Teradata |
| TIMEZONE_HOUR | SQL-2016 | — | Mimer | — | — | — | — | Teradata |
| TIMEZONE_MINUTE | SQL-2016 | — | Mimer | — | — | — | — | Teradata |
| TINYBLOB | — | — | — | MySQL | — | — | — | — |
| TINYINT | — | — | — | MySQL | — | — | — | — |
| TINYTEXT | — | — | — | MySQL | — | — | — | — |
| TITLE | — | — | — | — | — | — | — | Teradata |
| TO | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| TOP | — | — | — | — | — | — | SQL Server | — |
| TRACE | — | — | — | — | — | — | — | Teradata |
| TRAILING | SQL-2016 | — | Mimer | MySQL | — | PostgreSQL | — | Teradata |
| TRAN | — | — | — | — | — | — | SQL Server | — |
| TRANSACTION | — | — | — | — | — | — | SQL Server | Teradata |
| TRANSLATE | SQL-2016 | — | — | — | — | — | — | Teradata |
| TRANSLATE_CHK | — | — | — | — | — | — | — | Teradata |
| TRANSLATE_REGEX | SQL-2016 | — | — | — | — | — | — | — |
| TRANSLATION | SQL-2016 | — | — | — | — | — | — | Teradata |
| TREAT | SQL-2016 | — | Mimer | — | — | — | — | Teradata |
| TRIGGER | SQL-2016 | DB2 | Mimer | MySQL | Oracle | — | SQL Server | Teradata |
| TRIM | SQL-2016 | — | — | — | — | — | — | Teradata |
| TRIM_ARRAY | SQL-2016 | — | — | — | — | — | — | — |
| TRUE | SQL-2016 | — | Mimer | MySQL | — | PostgreSQL | — | Teradata |
| TRUNCATE | SQL-2016 | DB2 | — | — | — | — | SQL Server | — |
| TRY_CONVERT | — | — | — | — | — | — | SQL Server | — |
| TSEQUAL | — | — | — | — | — | — | SQL Server | — |
| TYPE | — | DB2 | — | — | — | — | — | Teradata |
| UC | — | — | — | — | — | — | — | Teradata |
| UESCAPE | SQL-2016 | — | — | — | — | — | — | — |
| UID | — | — | — | — | Oracle | — | — | — |
| UNDEFINED | — | — | — | — | — | — | — | Teradata |
| UNDER | — | — | — | — | — | — | — | Teradata |
| UNDO | — | DB2 | — | MySQL | — | — | — | Teradata |
| UNION | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| UNIQUE | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| UNKNOWN | SQL-2016 | — | Mimer | — | — | — | — | Teradata |
| UNLOCK | — | — | — | MySQL | — | — | — | — |
| UNNEST | SQL-2016 | — | — | — | — | — | — | Teradata |
| UNPIVOT | — | — | — | — | — | — | SQL Server | — |
| UNSIGNED | — | — | — | MySQL | — | — | — | — |
| UNTIL | SQL/PSM-2016 | DB2 | Mimer | — | — | — | — | Teradata |
| UPD | — | — | — | — | — | — | — | Teradata |
| UPDATE | SQL-2016 | DB2 | Mimer | MySQL | Oracle | — | SQL Server | Teradata |
| UPDATETEXT | — | — | — | — | — | — | SQL Server | — |
| UPPER | SQL-2016 | — | — | — | — | — | — | Teradata |
| UPPERCASE | — | — | — | — | — | — | — | Teradata |
| USAGE | — | — | — | MySQL | — | — | — | Teradata |
| USE | — | — | — | MySQL | — | — | SQL Server | — |
| USER | SQL-2016 | DB2 | Mimer | — | Oracle | PostgreSQL | SQL Server | Teradata |
| USING | SQL-2016 | DB2 | Mimer | MySQL | — | PostgreSQL | — | Teradata |
| UTC_DATE | — | — | — | MySQL | — | — | — | — |
| UTC_TIME | — | — | — | MySQL | — | — | — | — |
| UTC_TIMESTAMP | — | — | — | MySQL | — | — | — | — |
| VALIDATE | — | — | — | — | Oracle | — | — | — |
| VALIDPROC | — | DB2 | — | — | — | — | — | — |
| VALUE | SQL-2016 | DB2 | Mimer | — | — | — | — | Teradata |
| VALUES | SQL-2016 | DB2 | Mimer | MySQL | Oracle | — | SQL Server | Teradata |
| VALUE_OF | SQL-2016 | — | — | — | — | — | — | — |
| VARBINARY | SQL-2016 | — | — | MySQL | — | — | — | — |
| VARBYTE | — | — | — | — | — | — | — | Teradata |
| VARCHAR | SQL-2016 | — | — | MySQL | Oracle | — | — | Teradata |
| VARCHAR2 | — | — | — | — | Oracle | — | — | — |
| VARCHARACTER | — | — | — | MySQL | — | — | — | — |
| VARGRAPHIC | — | — | — | — | — | — | — | Teradata |
| VARIABLE | — | DB2 | — | — | — | — | — | Teradata |
| VARIADIC | — | — | — | — | — | PostgreSQL | — | — |
| VARIANT | — | DB2 | — | — | — | — | — | — |
| VARYING | SQL-2016 | — | Mimer | MySQL | — | — | SQL Server | Teradata |
| VAR_POP | SQL-2016 | — | — | — | — | — | — | Teradata |
| VAR_SAMP | SQL-2016 | — | — | — | — | — | — | Teradata |
| VCAT | — | DB2 | — | — | — | — | — | — |
| VERBOSE | — | — | — | — | — | PostgreSQL | — | — |
| VERSIONING | SQL-2016 | DB2 | — | — | — | — | — | — |
| VIEW | — | DB2 | — | — | Oracle | — | SQL Server | Teradata |
| VIRTUAL | — | — | — | MySQL | — | — | — | — |
| VOLATILE | — | DB2 | — | — | — | — | — | Teradata |
| VOLUMES | — | DB2 | — | — | — | — | — | — |
| WAIT | — | — | — | — | — | — | — | Teradata |
| WAITFOR | — | — | — | — | — | — | SQL Server | — |
| WHEN | SQL-2016 | DB2 | Mimer | MySQL | — | PostgreSQL | SQL Server | Teradata |
| WHENEVER | SQL-2016 | DB2 | — | — | Oracle | — | — | Teradata |
| WHERE | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| WHILE | SQL/PSM-2016 | DB2 | Mimer | MySQL | — | — | SQL Server | Teradata |
| WIDTH_BUCKET | SQL-2016 | — | — | — | — | — | — | Teradata |
| WINDOW | SQL-2016 | — | — | MySQL | — | PostgreSQL | — | — |
| WITH | SQL-2016 | DB2 | Mimer | MySQL | Oracle | PostgreSQL | SQL Server | Teradata |
| WITHIN | SQL-2016 | — | — | — | — | — | — | — |
| WITHIN_GROUP | — | — | — | — | — | — | SQL Server | — |
| WITHOUT | SQL-2016 | — | Mimer | — | — | — | — | Teradata |
| WLM | — | DB2 | — | — | — | — | — | — |
| WORK | — | — | — | — | — | — | — | Teradata |
| WRITE | — | — | — | MySQL | — | — | — | Teradata |
| WRITETEXT | — | — | — | — | — | — | SQL Server | — |
| XMLCAST | — | DB2 | — | — | — | — | — | — |
| XMLEXISTS | — | DB2 | — | — | — | — | — | — |
| XMLNAMESPACES | — | DB2 | — | — | — | — | — | — |
| XOR | — | — | — | MySQL | — | — | — | — |
| YEAR | SQL-2016 | DB2 | Mimer | — | — | — | — | Teradata |
| YEARS | — | DB2 | — | — | — | — | — | — |
| YEAR_MONTH | — | — | — | MySQL | — | — | — | — |
| ZEROFILL | — | — | — | MySQL | — | — | — | — |
| ZEROIFNULL | — | — | — | — | — | — | — | Teradata |
| ZONE | — | DB2 | — | — | — | — | — | Teradata |